
Тупит vCenter из-за сбойного Datastore Dell
![]()
Добрый день! Уважаемые читатели и гости IT блога Pyatilistnik.org. В прошлый раз мы с вами разобрали установку Hyper-V в Windows 11, чтобы иметь возможность использования гипервизора второго типа. Сегодня я хочу с вами поделиться интересным опытом, когда ваш vCenter сервер может вести себя очень непредсказуемо, мешав нормальной работе с серверами виртуализации. Я покажу, как и где можно найти информацию по причине и как можно ее исправить.
❌Описание проблемы
И так есть vCenter Server 7 и рядом кластеров ESXI. Проснувшись утром я обычно проверяю данные системы мониторинга Zabbix на предмет возможных проблем. В итоге я обнаружил, что часть серверов перестали отвечать по сети (Ping). Подключившись к vCenter я полез в консоль на один из таких серверов. На первом был синий экран hal initialization failed.
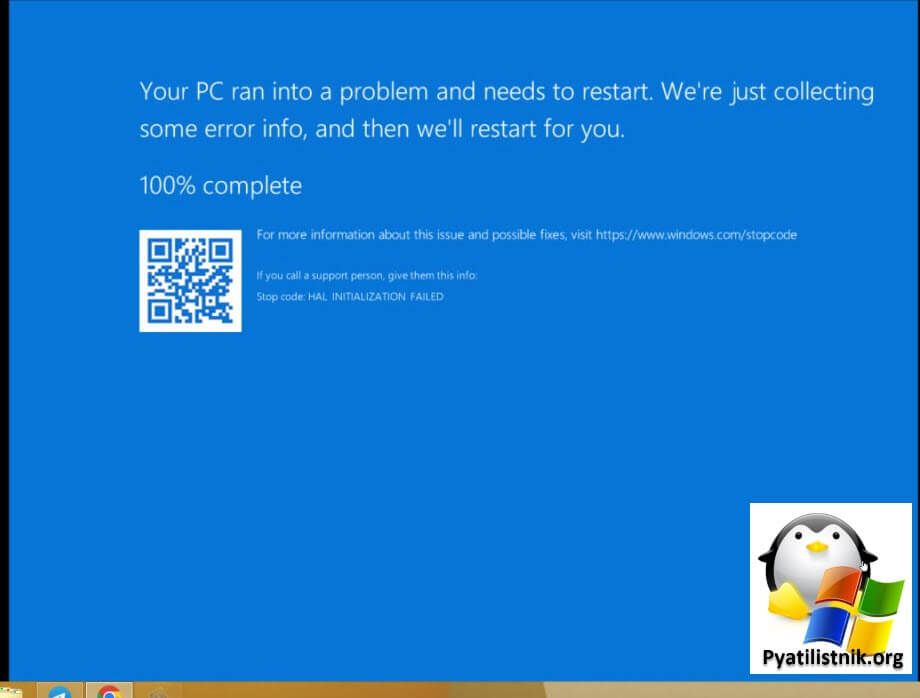
На втором был черный экран с постоянно загружающимся колесом загрузки.

При попытке произвести принудительный ресет виртуальной машины с синим экраном, а потом и других задание очень долго висело со статусом Executing callbacks.
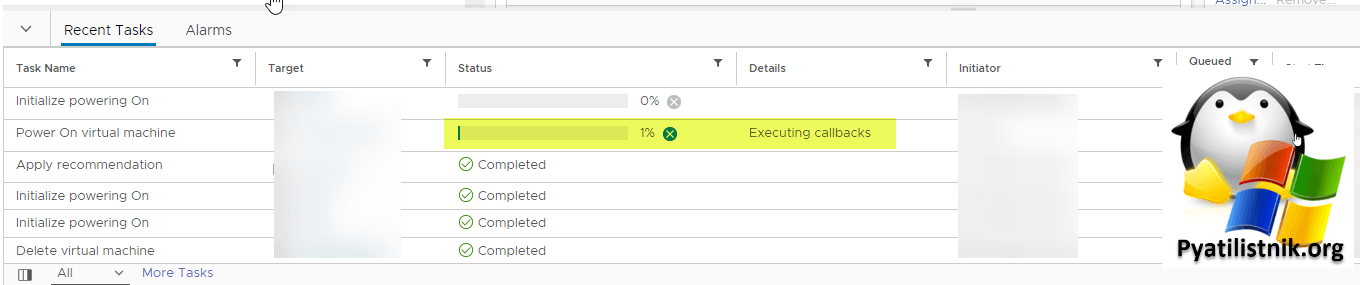
Так же периодически часть виртуальных серверов начинала флапать, то есть они перестали отвечать по сети на какое-то время. Любая штатная перезагрузка виртуальной машины из операционной системы, так же приводила к длительным черным экранам, что сильно напрягало. Я никогда не видел, чтобы vCenter так колбасило.
Даже при попытке мигрировать данные виртуальные машины или другие, так же задания имели статус Executing callbacks.
👀Как искать проблему?
Первым делом нужно изучить логи. Смотреть логи у виртуальной машины было бесполезно, так как дело было явно шире чем ее рамки работы. Поэтому я посмотрел на каком хосте располагались сбойные сервера, они были распределены между несколькими ESXI.
- 1️⃣Первое, что вы должны сделать, это включить ssh доступ к ESXI
- 2️⃣Подключиться по ssh и вытащить журналы логов в папке var. (К сожалению веб-интерфейс не всегда может работать, чтобы смотреть логи там)
Нас будет интересовать файл vmkernel.log. Там меня привлекло очень частое упоминание ошибки:
- Тут видно, что есть проблемы с датастором DELL_07, лун naa.6000d31005ba5c000000000002200015
2022-08-23T03:35:21.212Z cpu61:2097664)StorageDevice: 7059: End path evaluation for device naa.6000d31005ba5c000000000002200015
2022-08-23T03:35:21.393Z cpu17:2097684)qlnativefc: vmhba4(3b:0.1): C0:T1:L48: Abort command succeeded -- 1
2022-08-23T03:35:21.950Z cpu45:3591914)HBX: 3058: 'DELL_07': HB at offset 3702784 - Waiting for timed out HB:
2022-08-23T03:35:21.950Z cpu45:3591914) [HB state abcdef02 offset 3702784 gen 60311 stampUS 12775952935048 uuid 624122cf-73cc98ea-1b3d-e43d1a2be3ea jrnl <FB 16777226> drv 24.82 lockImpl 4 ip 10.67.105.111]
2022-08-23T03:35:31.951Z cpu53:3591914)HBX: 3058: 'DELL_07': HB at offset 3702784 - Waiting for timed out HB:
2022-08-23T03:35:31.951Z cpu53:3591914) [HB state abcdef02 offset 3702784 gen 60311 stampUS 12775952935048 uuid 624122cf-73cc98ea-1b3d-e43d1a2be3ea jrnl <FB 16777226> drv 24.82 lockImpl 4 ip 10.67.105.111]
2022-08-23T03:35:32.234Z cpu17:2097684)qlnativefc: vmhba4(3b:0.1): Task Mgmt abort on serial num 20a536b
2022-08-23T03:35:32.234Z cpu17:2097684)qlnativefc: vmhba4(3b:0.1): C0:T1:L2: Abort command succeeded -- 0
2022-08-23T03:35:32.238Z cpu13:2097257)ScsiDeviceIO: 4148: Cmd(0x45b9c21acd08) 0x84, cmdId.initiator=0x43090aea2060 CmdSN 0x20a536b from world 0 to dev "naa.6000d31005ba5c000000000002200029" failed H:0x5 D:0x0 P:0x0. Cmd count Active:0 Queued:0
2022-08-23T03:35:41.953Z cpu55:3591914)HBX: 3058: 'DELL_07': HB at offset 3702784 - Waiting for timed out HB:
- А вот тут мы видим статус H:0x3 D:0x0 P:0x0
2022-08-23T08:37:20.031Z cpu53:3603068)qlnativefc: vmhba3(3b:0.0): C0:T1:L48 - FCP command status: 0x5-0x0 (0x8) portid=020101 oxid=0x6cf cdb=a30a00 len=3064 rspInfo=0x0 resid=0x0 fwResid=0x0 host status = 0x8 device status = 0x0
2022-08-23T08:37:20.231Z cpu56:2097685)qlnativefc: vmhba3(3b:0.0): C0:T1:L48: Abort command succeeded -- 1
2022-08-23T08:37:20.231Z cpu49:2097664)ScsiPath: 6814: Command 0xa3 (cmdSN 0x0, World 0) to path vmhba3:C0:T1:L48 timed out: expiry time occurs 203ms in the past
2022-08-23T08:37:20.231Z cpu71:2097299)NMP: nmp_ThrottleLogForDevice:3815: last error status from device naa.6000d31005ba5c000000003300000015 repeated 1 times
2022-08-23T08:37:20.231Z cpu71:2097299)NMP: nmp_ThrottleLogForDevice:3867: Cmd 0xa3 (0x45d99fcf3288, 0) to dev "naa.6000d31005ba5c000000003300000015" on path "vmhba3:C0:T1:L48" Failed:
2022-08-23T08:37:20.231Z cpu71:2097299)NMP: nmp_ThrottleLogForDevice:3875: H:0x3 D:0x0 P:0x0. Act:NONE. cmdId.initiator=0x45395001bbc8 CmdSN 0x0
2022-08-23T08:37:20.231Z cpu49:2097664)VMW_SATP_ALUA: satp_alua_issueCommandOnPath:736: Path "vmhba3:C0:T1:L48" (UP) command 0xa3 failed with status Timeout. H:0x3 D:0x0 P:0x0 .
2022-08-23T08:37:26.075Z cpu62:3591914)HBX: 3058: 'DELL_07': HB at offset 3702784 - Waiting for timed out HB:
2022-08-23T08:37:26.075Z cpu62:3591914) [HB state abcdef02 offset 3702784 gen 60311 stampUS 12775952935048 uuid 624122cf-73cc98ea-1b3d-e43d1a2be3ea jrnl <FB 16777226> drv 24.82 lockImpl 4 ip 10.67.105.111]
2022-08-23T08:37:30.235Z cpu56:2097685)qlnativefc: vmhba4(3b:0.1): Task Mgmt abort on serial num 0
2022-08-23T08:37:30.235Z cpu56:2097685)qlnativefc: vmhba4(3b:0.1): SCSI command timeout counter incremented to 403
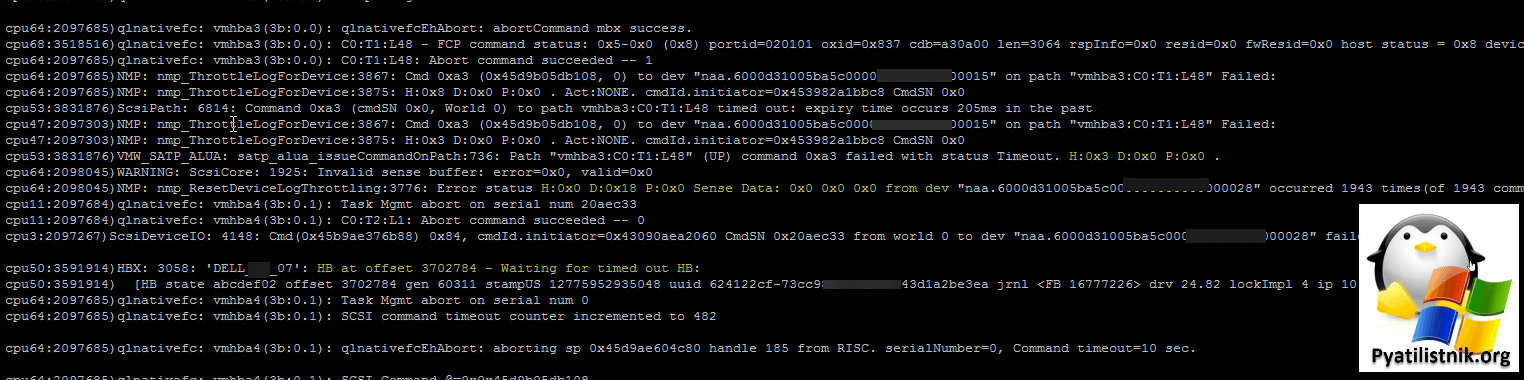
2022-08-23T03:30:12.216Z cpu60:2098045)NMP: nmp_ResetDeviceLogThrottling:3782: last error status from device naa.6000d31005ba5c000000000033000015 repeated 1 times
2022-08-23T03:30:21.877Z cpu64:3591914)HBX: 3058: 'DELL_07': HB at offset 3702784 - Waiting for timed out HB:
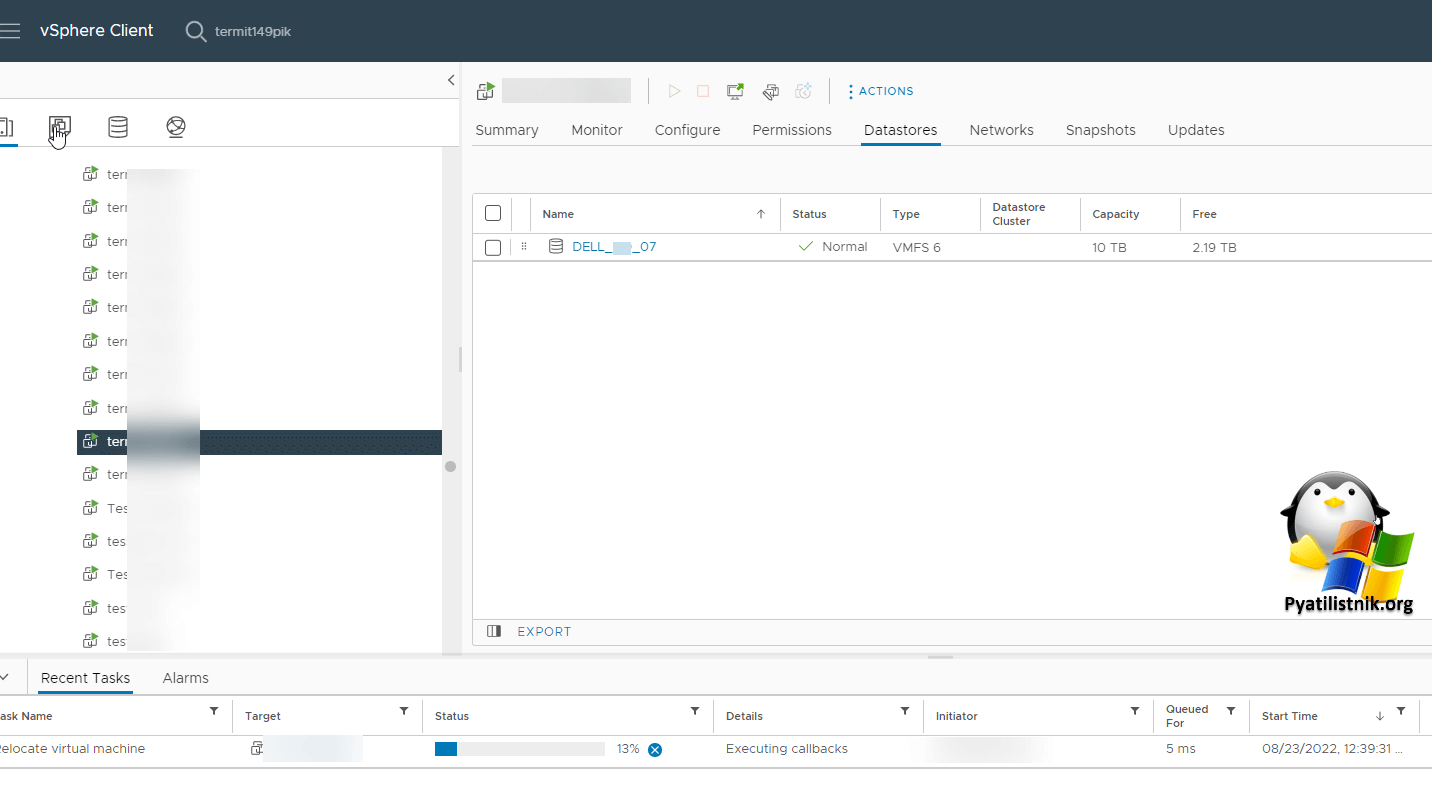
Когда я стал проверять в vCenter данный датастор, то обнаружил, что сбойные виртуальные машины, которые либо не отвечали по сети, либо постоянно флапали располагались именно там.
Начав поиск ошибки Waiting for timed out HB мои поиски привели меня на сайт:
Тут указав свои параметры из ошибки H:0x3 D:0x0 P:0x0 и H:0x0 D:0x18 P:0x0 вы можете получить расшифровку данного кода.
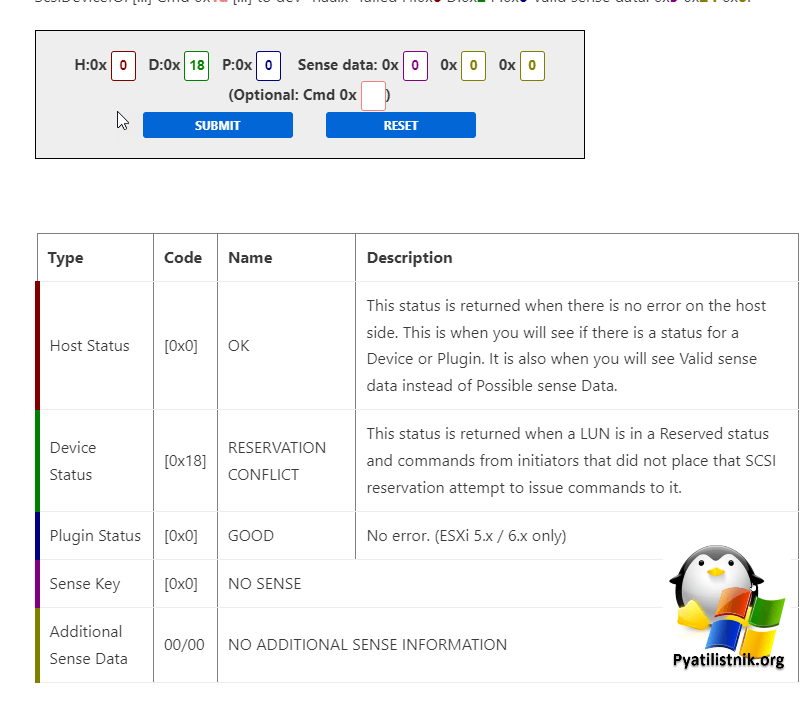
Получилось, что код [0x18] - это RESERVATION CONFLICT. Этот статус возвращается, когда LUN находится в состоянии Reserved и команды от инициаторов, которые не размещали это резервирование SCSI, пытаются передать ему команды. Что НАМ говорит, о проблеме на системе хранения данных. Код [0x3] со статусом TIME_OUT возвращается когда, истекает время ожидания команды к массиву.
Подключившись по ssh к ESXI хосту, где располагались проблемные виртуальные машины и попытавшись посмотреть в esxtop, что происходит. Тут я увидел невооруженным взглядом, что огромные значения CPU WAIT. Процессор просто курит в сторонке и чего-то ждет, а ждет как мы поняли он ответа от дисков.
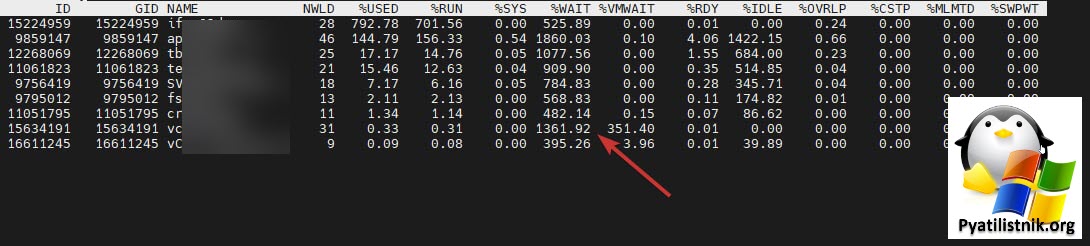
Так же в esxtop можно нажать shift-v и посмотреть более детально.
Пока делали диагностику системы хранения данных, решили рядом восстановить виртуальные машины, которые зацепил сбойный LUN. Для этого у нас есть сервер Veeam 11. При попытке выполнить восстановление на кластер, где располагались сбойные сервера, но на другую СХД, мы получили ошибку.
Soap fault. No such host is known. Detail: 'getaddrinfo failed in tcp_connect()', endpoint: 'https://vcenter:443/sdk'
SOAP connection is not available. Connection ID: [vcenter].
Failed to create NFC upload stream. NFC path: [nfc://conn:vcenter,nfchost:host-506433,stg:datastore-490430@Term01-R/Term01-R.vmx].
--tr:Failed to create target file [nfc://conn:vcenter,nfchost:host-506433,stg:datastore-490430@Term01-R/Term01-R.vmx]
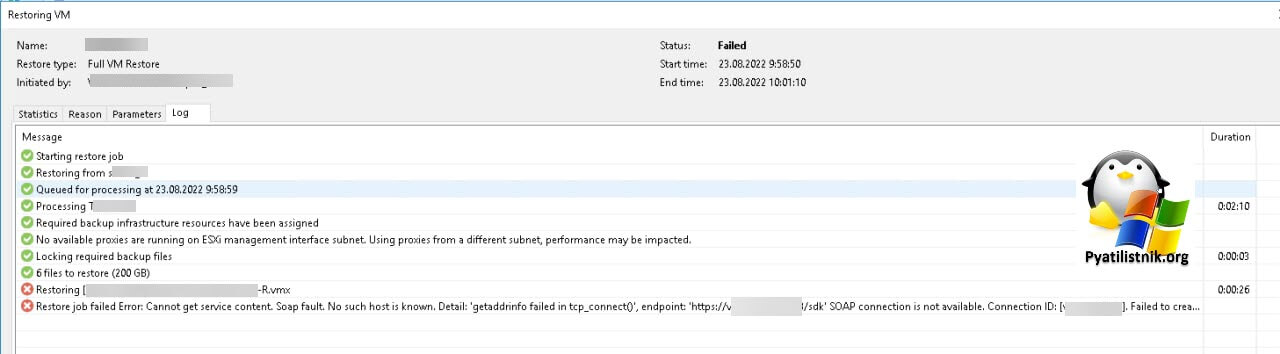
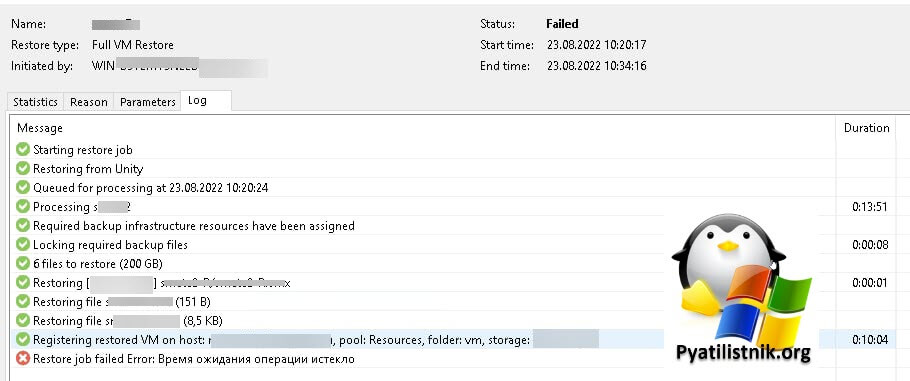
При данной ошибке, очень важно проверить:
- 1️⃣На сервере Veeam обязательно проверьте доступность порта 902 со стороны хосту ESXI куда идет восстановление
- 2️⃣Убедитесь через команду nslookup, с Veeam сервера, что DNS-имя ESXI хоста корректно разрешается, если будут ошибки, то нужно смотреть свои DNS-серверы, отвечающие за это
- 3️⃣Убедитесь, что ваше антивирусное решение на vCenter сервере, на сервере Veeam не блокирует данную операцию, что исключены все папки Veeam в нем.
- 4️⃣Убедитесь в правильности учетной записи из под которой идет восстановление
- 5️⃣Убедитесь, что не блокируется порт 443 между удаленным прокси-сервером Veeam и сервером vCenter
- 6️⃣Можно изучить логи на сервере Veeam в папке %programdata%\Veeam\Backup
Как временное решение удалось восстановить у виртуальных машин отдельно диски и прицепить их к новой виртуальной машине, но это костыль.
🛠Как устранить проблему
- 1️⃣Первое, что нужно чинить, это систему хранения данных
- 2️⃣Как временное решение вы можете удалить из vCenter сбойных датастор, если получиться. Для этого выберите ESXi или отдельный кластер. Перейдите в раздел Datastores, выберите нужный LUN и произведите ему процедуру "Unmount Datastore".
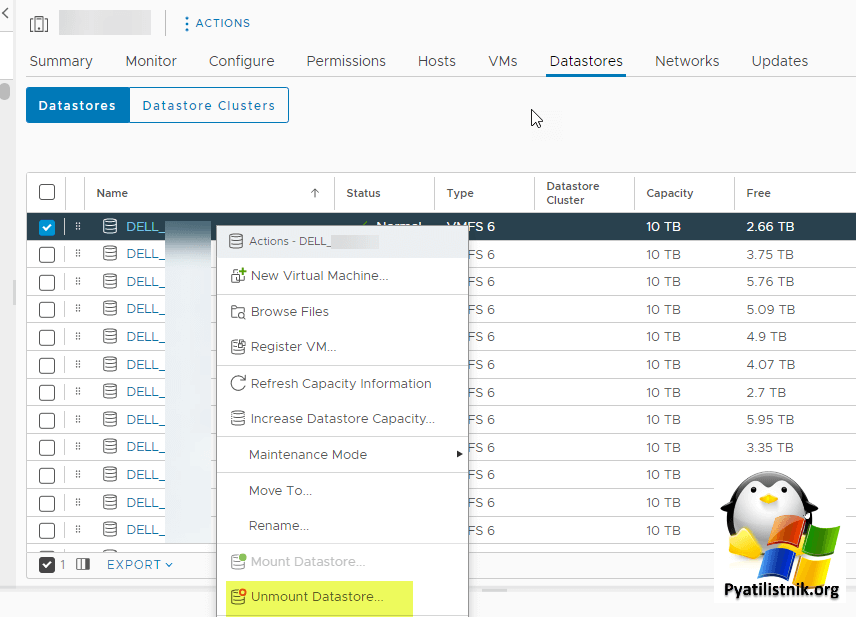
Через некоторое время нам удалось починить СХД (Dell Data Domain), в итоге увеличили параметр для создания снапшотов.
Что делали, тут применяются команды Dell Storage Center Command.
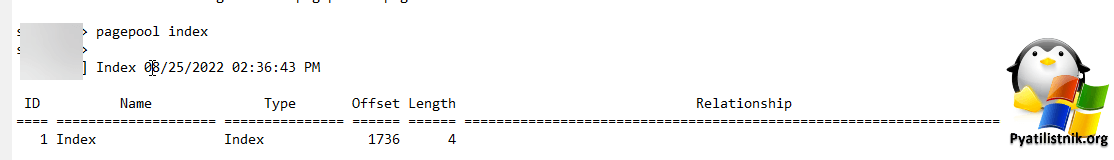
Получаем доступ в режиме разработчика
Команда pagepool set 1 121 4096 на СХД DELL SC5020 устанавливает размер буферного пула (page pool) для 1-го индекса на значение 4096. Буферный пул используется для временного хранения данных и ускорения операций ввода-вывода на системе хранения данных. Установка размера буферного пула влияет на производительность и эффективность работы системы хранения.
- Тут "1" - это номер индекса
- 121 - номер параметра
- 4096 - размер параметра

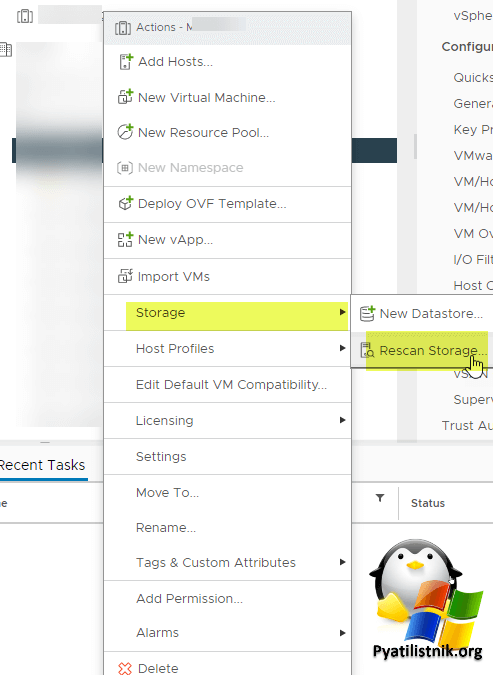
После починки СХД, на всех хостах и кластерах нужно сделать сканирование датасторов. Для этого выберите кластер "Storage - Rescan Storage"
Или еще можно сделать на отдельном ESXI хосте, перейти в "Configure - Storage Devices" и нажать Refresh.
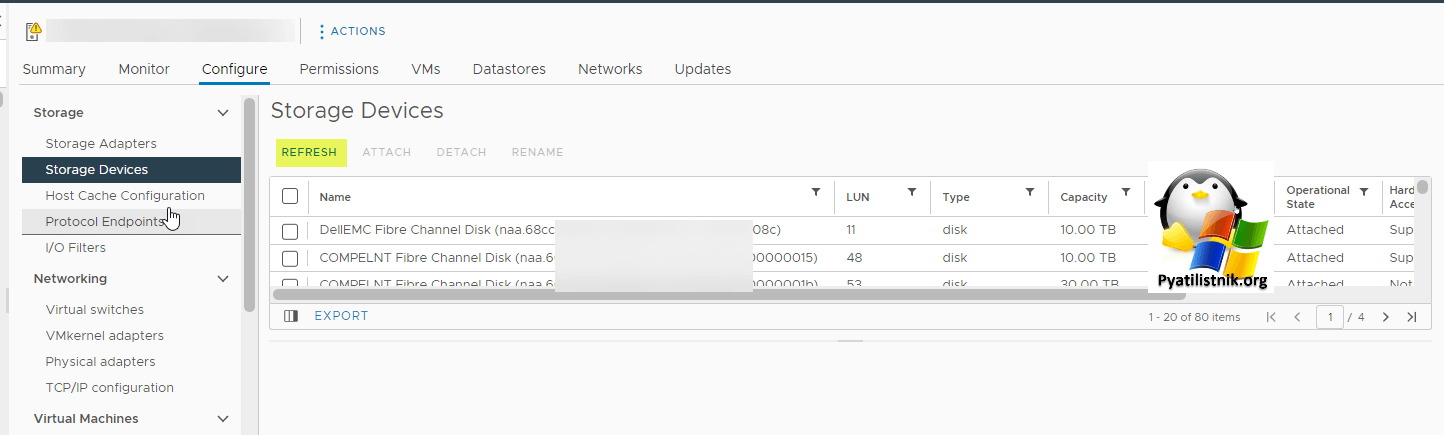
Если у вас кластер, то можно на нем запустить сканирование всех VMFS томов.

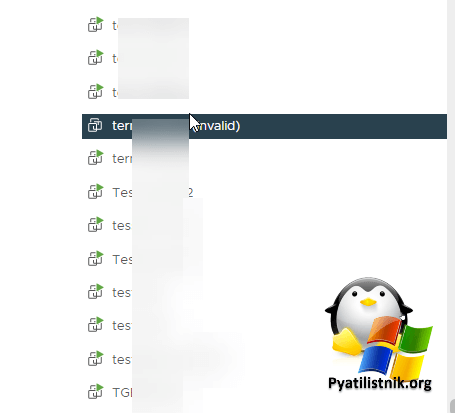
Еще кстати после восстановления СХД на некоторых виртуальных машинах может появиться статус Invalid.
Вывод
- Всегда мониторить ошибки на СХД
- В случае невозможности починить оперативно СХД, попробовать оторвать LUN
- Если у вас несколько таких СХД или пулов, обязательно проверьте на нем данный параметр
Дополнительные ссылки
- https://www.veeam.com/kb1198
- Список портов Veeam и vCenter- https://helpcenter.veeam.com/archive/backup/95u4/vsphere/used_ports.html
- https://kb.vmware.com/s/article/1003988
- https://kb.vmware.com/s/article/2032823
- https://kb.vmware.com/s/article/2144962
- https://kb.vmware.com/s/article/1002293
На этом у меня все, надеюсь, что вы то же смогли решить свои сложности в работе vCenter сервер. С вами был Иван Сёмин, автор и создатель IT проекта Pyatilistnik.org.
