
Ошибка The cluster Resource Hosting Subsystem (RHS) process was terminated and will be restarted
![]() Добрый день! Уважаемые читатели и гости IT блога Pyatilistnik.org. В прошлый раз мы с вами устранили ошибку обновления Windows 0x800705b4. Сегодня я хочу вам показать свой опыт решения одной интересной проблемы связанный с кластером MS SQL 2019, который я получил на этой неделе тарблшутинга. Суть такая, есть ряд физических серверов на базе Dell Poweredge R740, на них установлен Windows Server 2019 с MS SQL 2019. Все это объединено в отказоустойчивый кластер AlwaysOn. В какой-то момент при переводе инстанса с одного узла на другой через некоторое время работы инстанс переставал отвечать и сервер зависал. Давайте смотреть в чем было дело.
Добрый день! Уважаемые читатели и гости IT блога Pyatilistnik.org. В прошлый раз мы с вами устранили ошибку обновления Windows 0x800705b4. Сегодня я хочу вам показать свой опыт решения одной интересной проблемы связанный с кластером MS SQL 2019, который я получил на этой неделе тарблшутинга. Суть такая, есть ряд физических серверов на базе Dell Poweredge R740, на них установлен Windows Server 2019 с MS SQL 2019. Все это объединено в отказоустойчивый кластер AlwaysOn. В какой-то момент при переводе инстанса с одного узла на другой через некоторое время работы инстанс переставал отвечать и сервер зависал. Давайте смотреть в чем было дело.
Изучение логов FailoverClustering
Сразу после принудительной перезагрузки сервера с помощью IDRAC, в логах Windows вы должны обратить на такие события:
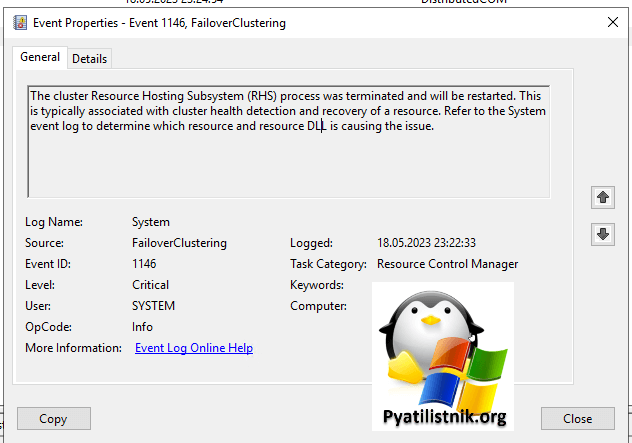

Based on the failure policies for the resource and role, the cluster service may try to bring the resource online on this node or move the group to another node of the cluster and then restart it. Check the resource and group state using Failover Cluster Manager or the Get-ClusterResource Windows PowerShell cmdlet.

Тут обязательно запомните время, оно пригодится при фильтрации логов за определенный период. Ранее я вам рассказывал как собирать логи с отказоустойчивого кластера через командлет Get-ClusterLog. Выведем логи со всех участников кластера за последние 10 часов.
Изучая лог я нашел вот такие интересные строки:
00002d44.00002d6c::2023/05/18-23:22:13.390 WARN [RHS - Timeout] Health Monitoring Failure : Resource SQL Server (DB1632) is not functioning as expected. Cancelling current operation and terminating the hosting RHS process to reload and recover the resource.
0000322c.00003230::2023/05/18-23:25:25.977 ERR [RES] Generic Service <SQL Server CEIP (DB1631)>: ResUtilRemoveResourceServiceEnvironment: Failed to open Services key, error = 19.
ERR [RES] Physical Disk: GetVolumeInformation(Q:\) failed: error 3
ERR [RES] SQL Server <SQL Server (DB1632)>: [sqsrvres] ODBC Error: [HYT00] [Microsoft][SQL Server Native Client 11.0]Query timeout expired (0)
ERR [RHS] RhsResType::NotifyAllResourceTypesMonitorIsShuttingDown: (1114)' because of 'Error loading resource DLL mqtgclus.dll.'
Как устранить проблему с зависанием инстанса MS SQL
Изучая лог мы пришли к выводу, что проблема состоит в FC карточке. В моем сервере была установлена Dell QLogic 2662 Dual Port 16GB.

После замены карточки и обновлению драйверов проблема ушла. Так же я нашел в одной из веток обсуждения, что есть некий параметр реестра по пути:
Там данному ключу присваивали значение 3. Это нам даст такое поведение: После настройки раздела реестра сервер, на котором возникает взаимоблокировка RHS, отображает синий экран и создает дамп памяти stop 0x9E. Затем вы можете проанализировать это и устранить причину.
Возможные решения
- Если время отклика диска при чтении или записи медленное (низкая производительность диска), обратитесь к поставщику хранилища.
- Если антивирус мешает онлайн-попытке, удалите и перезагрузите сервер, чтобы удалить драйверы фильтра.
- Необходимо обновить драйверы контроллера HBA или RAID.
- Разрешения на корневые диски отсутствуют.
- При наличии постоянных проблем с резервированием рекомендуется связаться с поставщиком хранилища для диагностики проблем.
Дополнительно
- https://learn.microsoft.com/en-us/answers/questions/879234/resource-control-manager-in-failover-cluster-error?utm_source=pocket_saves
- https://learn.microsoft.com/en-us/troubleshoot/windows-server/high-availability/troubleshoot-cannot-bring-physical-disk-online



