
Замена BBU на PowerStore 3000T

Всех вновь приветствую на страницах IT блога. Июль у меня выдался очень динамичным, в этом году. Сегодня я хочу с вами поделиться практическим опытом по траблшутингу и восстановлению работу системы хранения данных Dell PowerStore 3000T, его я запомню надолго. Началось все с события в системе мониторинга, которая переслала письма от СХД, в письмах были ошибки на BBU, через пару минут стали появляться события, о недоступности ряда виртуальных серверов, после которых я понял что, произошел глобальный сбой, о нем я поговорю ниже.
Критические ошибки на PowerStore 3000T
Полученных ошибок было очень много, вот самые частые из них.
Received message from "PS3000" with Subject "Alert Notification from appliance A1":
-------------------------
Database extension volume status (faulted)Error Code [0x01A00502]
Resource Type [cluster]
Resource Name [PS3000T]
Severity [Major]
Alert State [ACTIVE]
Timestamp [2025-07-12T19:16:40.637Z]Description:
Database extension volume is faultedSystem Impact:
Metrics collection will be disabled across the cluster until this fault is cleared.Repair Flow:
Please contact your service providerReference: DATABASE_EXTENSION_VOLUME_FAULTED [0x01A00502]
)
IMAPX1757 OK UID FETCH Completed.
Received message from "PS3000" with Subject "Alert Notification from appliance A1":
-------------------------
Port state has changed. (Down)Error Code [0x00307401]
Resource Type [FEPort]
Resource Name [BaseEnclosure-NodeA-IoModule0-FEPort1]
Severity [Info]
Alert State [CLEARED]
Timestamp [2025-07-12T19:10:18.427304Z]Description:
Port state has changed from down_in_use to up.Reference: XMS_FEPORT_PORT_STATE_UP [0x00307401]
)
IMAPX1761 OK UID FETCH Completed.
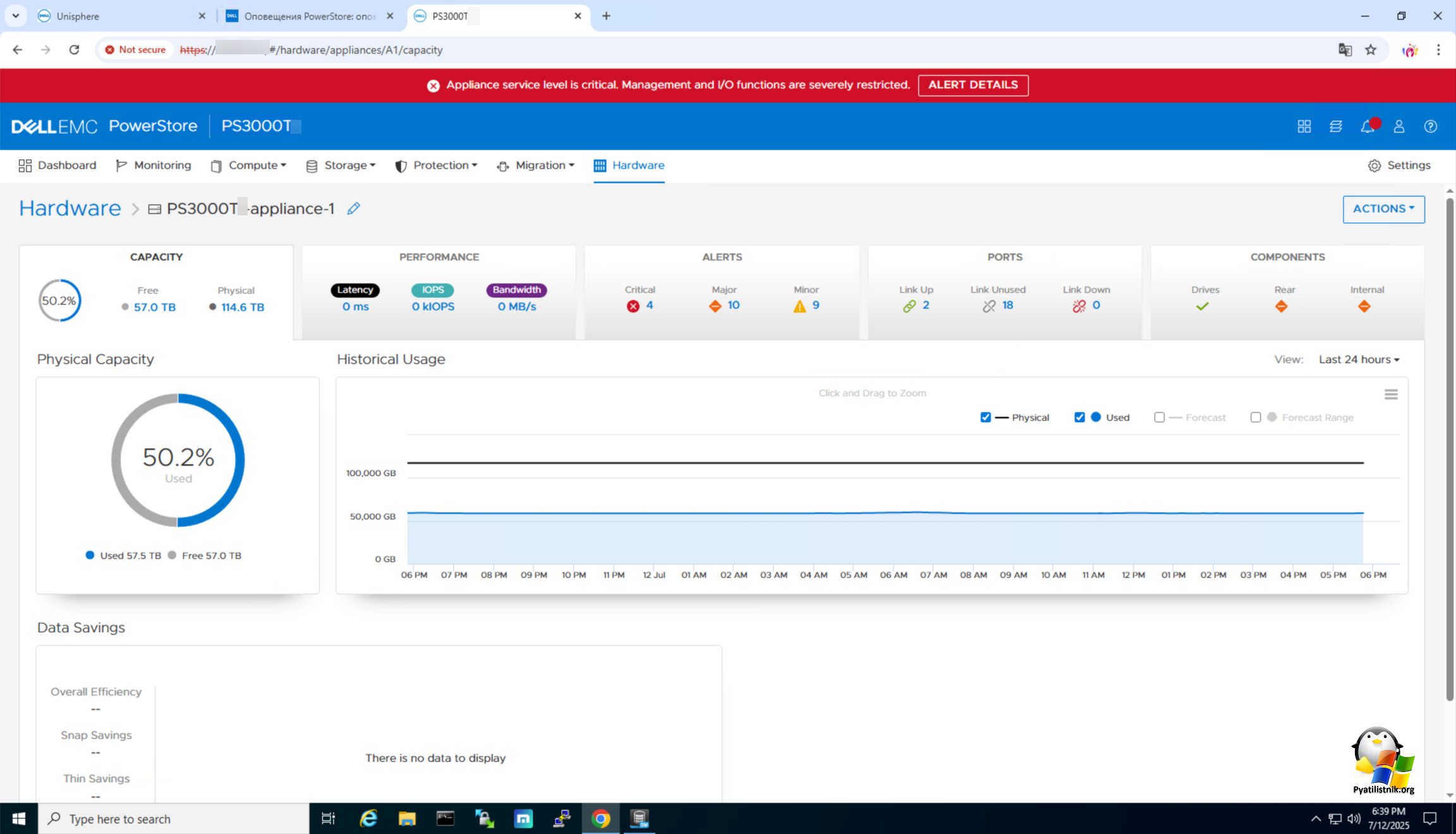
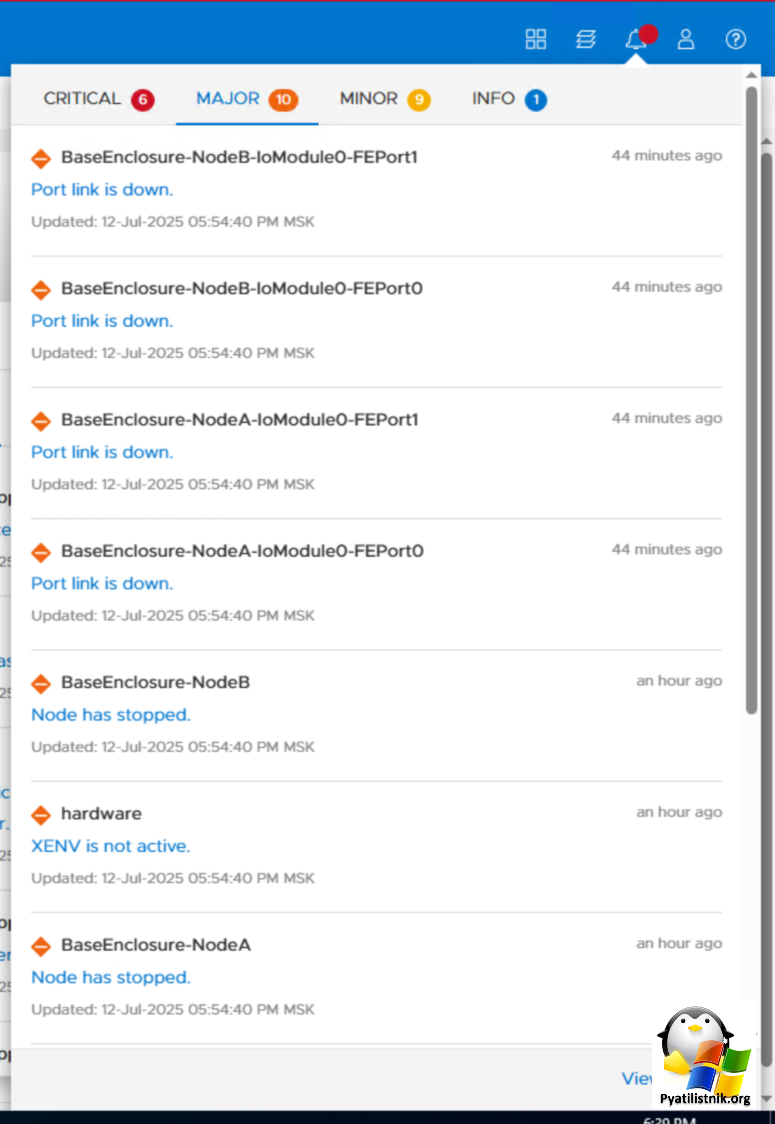
В веб интерфейсе видно, что система хранения отключила вес FC порты, в результате чего все LUN перестали быть доступны.
BaseEnclosure-NodeB-IoModule0-FEPort0 - Port link is down
BaseEnclosure-NodeB - Node has stopped
XENU is not active
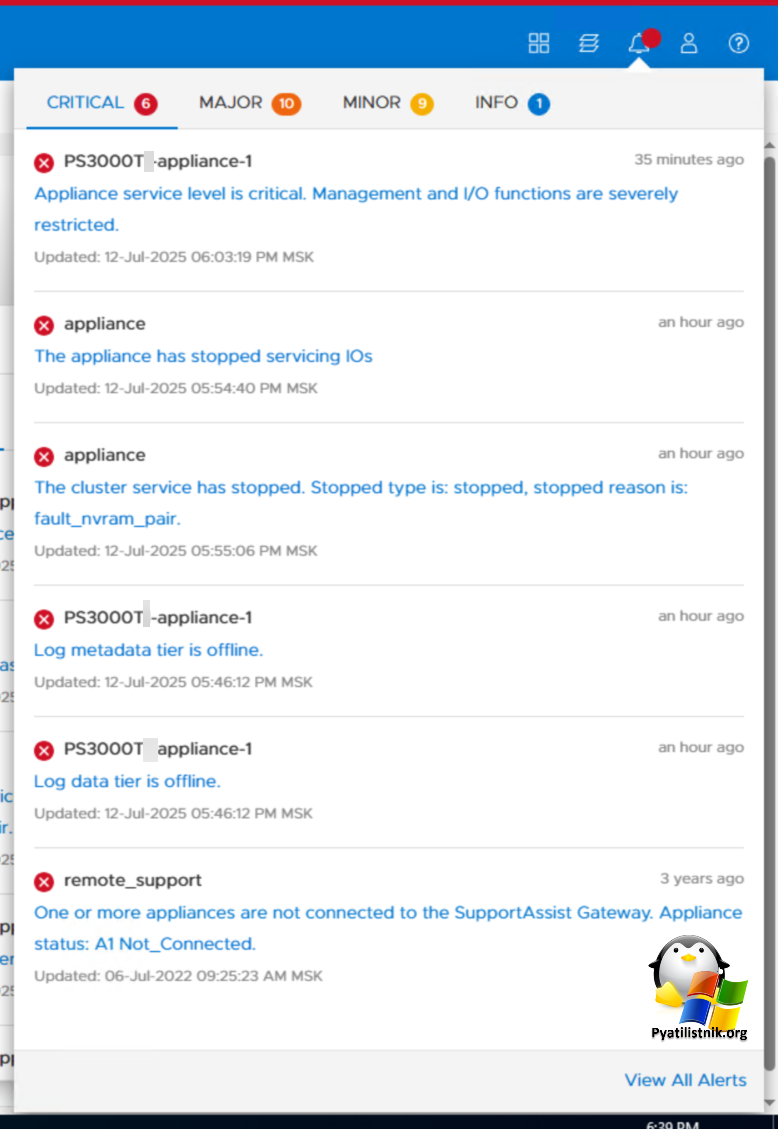
Appliance servicr leve is critical. Management and I/O functions are serverely restricted
The appliance has stopped servicing IOs
The cluster service has stopped. Stopped type is: fault_nvram_pair
Received message from "PS3000" with Subject "Alert Notification from appliance A1":
-------------------------
Node has stopped. (none)Error Code [0x00304201]
Resource Type [hardware]
Resource Name [BaseEnclosure-NodeB]
Severity [Info]
Alert State [CLEARED]
Timestamp [2025-07-12T19:09:10.273627Z]Description:
Node stop type was changed from none to none. Stop reason is: 291Reference: XMS_NODE_STOP_TYPE_NONE [0x00304201]
)
IMAPX1771 OK UID FETCH Completed.
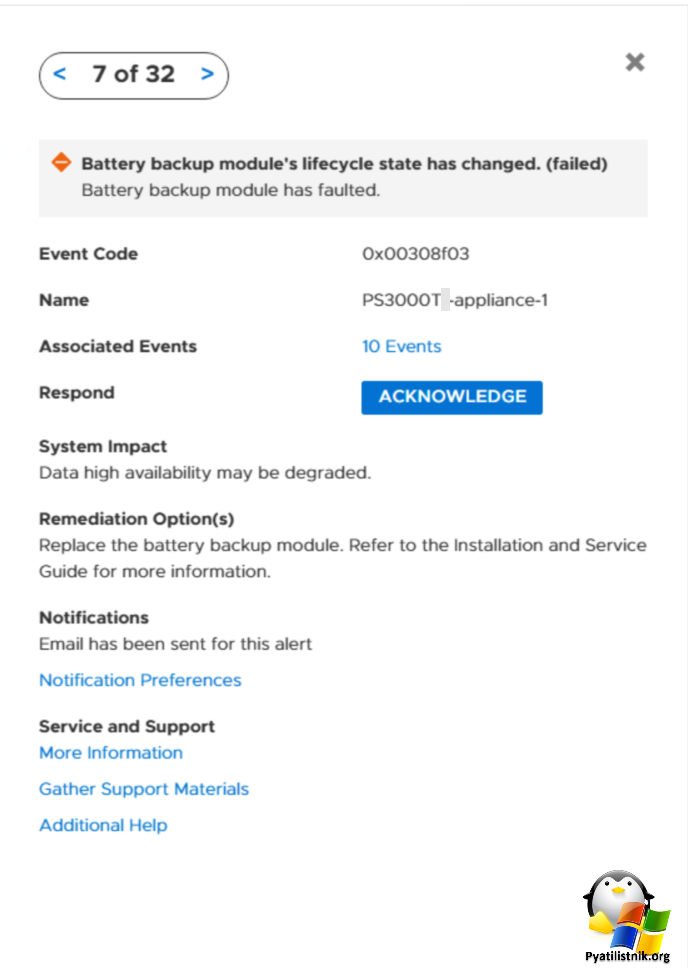
Received message from "PS3000" with Subject "Alert Notification from appliance A1":
-------------------------
Battery backup module's lifecycle state has changed. (failed)Error Code [0x00308F03]
Resource Type [hardware]
Resource Name [BaseEnclosure-NodeB-InternalBatteryBackupModule1]
Severity [Major]
Alert State [ACTIVE]
Timestamp [2025-07-12T14:55:34.132618Z]Description:
Battery backup module has faulted.System Impact:
Data high availability may be degraded.Repair Flow:
Replace the battery backup module. Refer to the Installation and Service Guide for more information.Reference: XMS_NODEBBU_FRU_STATE_FAILED [0x00308F03]
)
IMAPX1971 OK UID FETCH Completed.
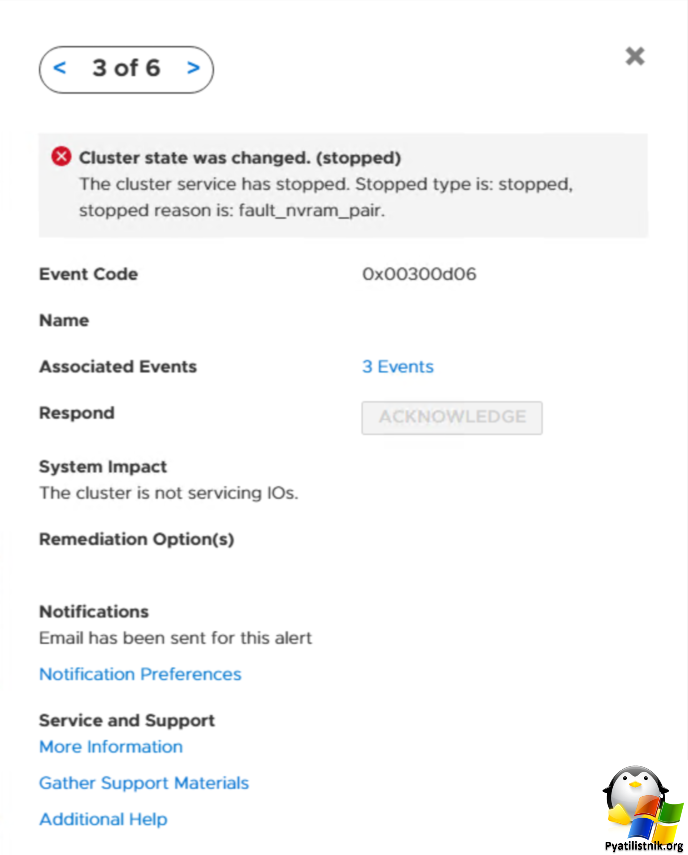
И еще куча разных кодов:
0x00b00703, 0x00300d06, 0x0030c601, 0x00200501, 0x00200401, 0x00307701
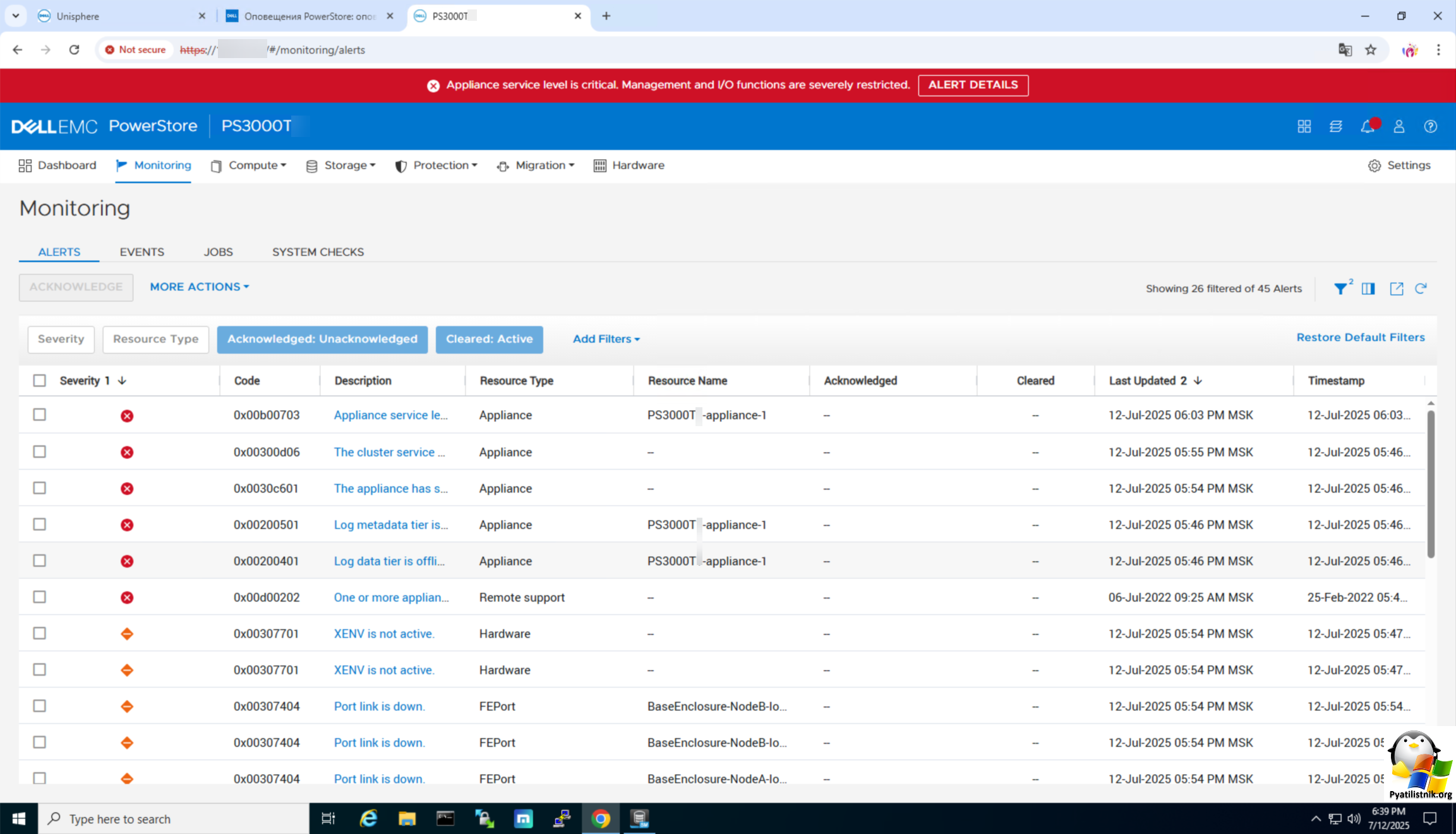
Причина аварийной ошибки 0x00b00703
Основной краеугольной ошибкой была 0x00b00703. Если обратиться к документации Dell, то там дается вот такое разъяснение.
https://www.dell.com/support/kbdoc/en-us/000132992/powerstore-alerts-cluster-monitor-service-states
Данное оповещение (0x00b00703) генерируется, когда система хранения переходит в автономный режим. В этом режиме отключается большая часть служб, доступ к LUN. В момент аварии я видел ошибки
Battery backup module's lifecycle state has changed. (failed)
Error Code [0x00308F03]
Resource Type [hardware]
Resource Name [BaseEnclosure-NodeB-InternalBatteryBackupModule1]
Severity [Major]
Alert State [ACTIVE]
Timestamp [2025-07-12T14:55:34.132618Z]Description:
Battery backup module has faulted.
Из нее видно, что есть проблема на BBU батарейке контроллера B, но у СХД, же есть и второй контроллер А, почему он не подхватил, вот был подвешенный вопрос. Параллельно мы заводили тикет к подрядчикам, и там коллеги подтвердили информацию.
По итогам изучения документов: ваши симптомы совпадают с ошибкой, описанной как проблема, исправленная в операционной системы версии 2.1.0.0 (у вас установлена 2.1.0.1), за одним исключением - в описании двойной отказ модулей BBU логический, а у вас - фактический. Таким образом, вы столкнулись с очень редким совпадением одновременного отказа двух жизненно важных компонентов (вендор предпринимает меры к тому, чтобы этого не случалось) и повторения ситуации не ожидается.
Давайте я подробно опишу как я понял эту ситуацию.
- У СХД PowerStore 3000T есть два кэширующих диска. Они используются для временного хранения часто запрашиваемых данных, что ускоряет операции чтения и записи. Запись данных сначала выполняется в кэш (на быстрые NVMe или SSD-диски), а затем асинхронно переносится на основное хранилище. Кэширующие диски работают в зеркалированной конфигурации (для защиты от сбоев).

- Данные в кэше могут быть сохранены даже при аварийном отключении питания (благодаря резервным батареям или флэш-накопителям с энергонезависимой памятью). Но на контроллере B, данная BBU приказала долго жить
- Сама система поймала редкий глюк, в результате чего второй контроллер A, решил, что у него так же проблемы и нужно все тушить, чтобы не потерять данные, которые хранятся в кэширующих дисках. Система посчитала, что проблема есть на двух батарейках. В результате чего я поймал автоновный режим работы, при котором доступ к данным отключается, чтобы они не повредились.

Небольшая справка: В СХД PowerStore 3000T вендор использует BBU из разных партий, чтобы исключить ситуацию с одновременным их выходом. Вот это поворот 🙂 Но как показала система относительности, сломаться может и из-за редкого глюка.
Что делать в подобной ситуации, тут все просто вам необходимо экстренно произвести замену BBU на нужном контроллере.
Перезагрузка обоих контроллеров вам не поможет, вы просто потеряете доступ к СХД в веб управление и ssh. Они просто не поднимутся как службы.
Читайте так же - Как менять батарейку на контроллере СХД Dell SC5020
Процедура замены BBU на контроллере PowerStore 3000T
Если у вас, как и у меня есть продуманный ЗИП и в нем есть BBU для PowerStore 3000T, то вам повезло, ну или ваши подрядчики готовы вам его предоставить максимально быстро. Если нет, то спешу вас расстроить, все ваши данные будут хоть и сохранены, но недоступны, такова жизнь, к сожалению.
Выше я показывал, что ошибки ссылаются на контроллер B (Resource Name [BaseEnclosure-NodeB-InternalBatteryBackupModule1]) поэтому приступаю к его извлечению и обслуживанию.
- На задней панели найдите с правой стороны пометку с буквой нужного контроллера. В моем случае это верхний контроллер B.
- Отключите все провода от нужного контроллера. Далее потяните специальный рычаг на себя, чтобы извлечь плату.
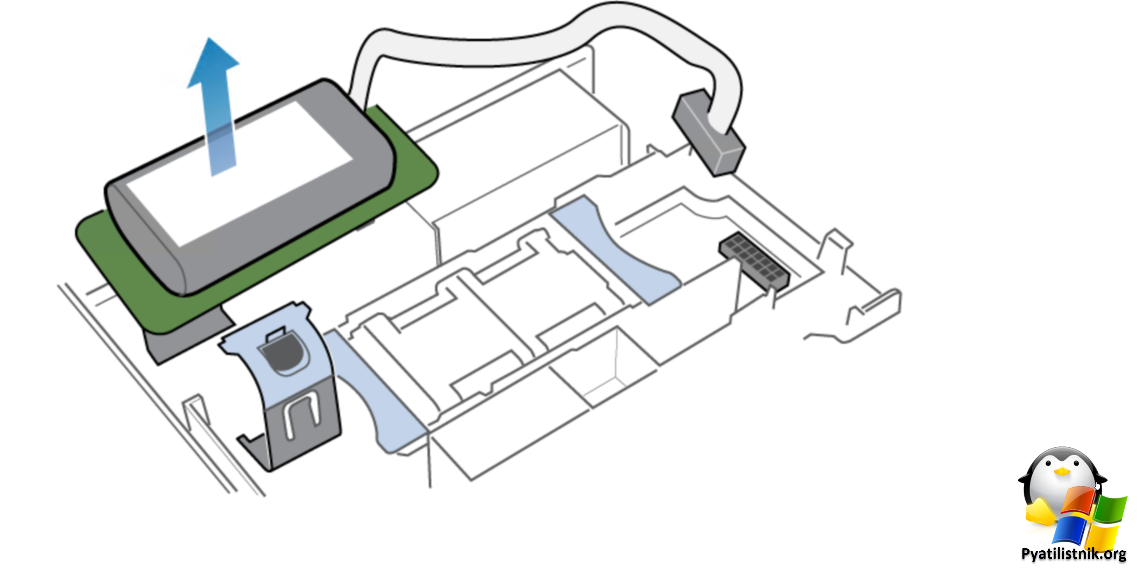
- Нажмите две кнопки, чтобы снять верхнюю крышку, с помощью круглых кнопок.
- BBU будет располагаться в верхней части платы
- Вот схема подключения батарейки к плате, у нее будет вот такой хвост ведущий к материнской плате.
- Готовьтесь, что придется как следует нажать на рычажок, чтобы отключить от материнской платы, но можете у вас будет проще и это мне так повезло.
- Далее устанавливаем новую батарейку и закрываем всю эту конструкцию. Для истории выложу фотографии самой BBU.










Включение контроллера после замены BBU
В моем случае после замены батарейки и подключения контроллера, СХД включилась сразу, индикация перешла из желтого состояния в синий, НО 20 минут все сервисы (web и ssh) были недоступны. И только после прохождения 20-ти минут я увидел долгожданный PING, сначала по IP-адресам контроллеров, затем и веб-служб управления.
После этого в vCenter я увидел пропавшие LUN со всеми виртуальными машинами. Параллельно к нам уже был подключен инженер подрядчика, который стал проверять статус текущего состояния и снимать логи, чтобы в дальнейшем их изучить.
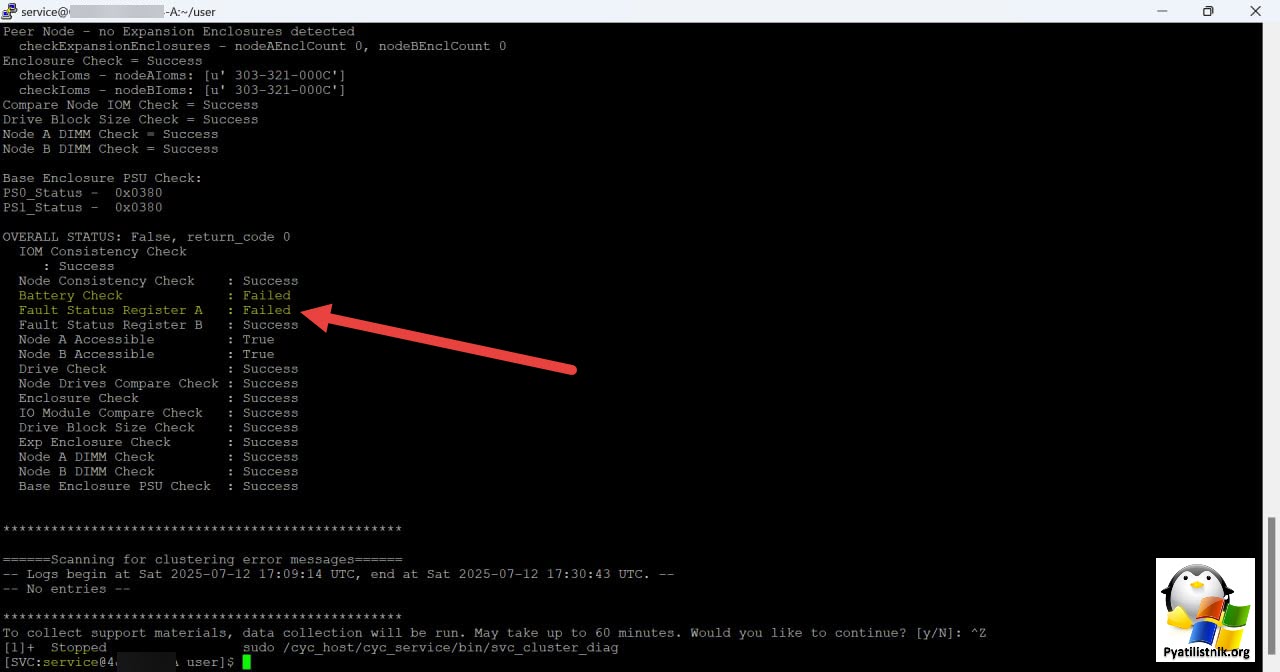
В первую очередь была выполнена команда для получения данных, о проверках состояния компонентов
svc_health_check list
И команда для извлечения архива с логами. Сюда попадет: системные, аппаратные, события ПО, настройки хранилища, сети, безопасности, данные о нагрузке, задержках, использовании ресурсов.
svc_dc run (--type=full --output=/path/to/save)
Напоминаю, что для подключения по ssh, в PowerStore используется специальный логин.
После самопроверки, я вижу, что с BBU Node B все хорошо, а вот с Node A не очень, она идет под замену. Тут планируются работы в данном направлении.
Что делать дальше
- Первое, что я буду делать это производить замену второй BBU
- Далее, чтобы избежать подобного глюка в будущем я буду прошивать данную СХД до новой версии, прошивку я уже получил, лежит в облаке.
- Подумаю с технической поддержкой, можно ли как то заранее было понять, что BBu выходит из строя
- Докупить ЗИП
Популярные Похожие записи:
- Ошибка The cluster Resource Hosting Subsystem (RHS) process was terminated and will be restarted
- Не запускается файловая роль на Failover Cluster
- Job failed because Job for this device is already present
- Не загружается контроллер Dell SC 5020
- Как отследить переезд файловых ролей на другой хост кластера
- Замена батарейки на Dell SC5020



