
Как скачать защищенный PDF файл с Google Диска, за минуту
- Постановка задачи
- Суть метода по скачиванию ограниченного PDF файла на Гугл диске
- Текст кода для скачивания защищенного PDF файла с Google Диска
- Как загрузить ограниченный PDF из Google Drive через Mozilla
- Как загрузить ограниченный PDF из Google Drive через Chrome
- Обновление скрипта от 22.11.2024
- Что делать если не работает в Chrome

Добрый день! Уважаемые читатели и гости одного из крупнейших IT блогов в России Pyatilistnik.org. В прошлый раз мы с вами научились запрещать автовоспроизведение видео в браузере Chrome, так как все понимают на сколько это может раздражать, и может быть несвоевременно, на Youtube для этого была отдельная кнопка, а вот в плане всего интернета пришлось выбирать любой из понравившихся методов. Сегодня я хочу вас научить скачивать защищенный PDF файл с Google Drive (Google Диска). Под защищенным понимается, что у вас есть возможность читать его с правами только на чтение и скачать или сохранить себе на Google диск вы его не можете. Но как выяснилось все очень просто решается и уже все придумано за нас.
Постановка задачи
И так у нас с вами есть ссылка на PDF файл, который располагается на облачном хранилище Google Диск, вот пример ссылки:
Как вы можете обратить внимание, это книга "Дешифровка критской письменности (Пеластско-лезгинский язык)". Все, что вы можете сделать это вызвать панель с меню и выбрать свойства документа.
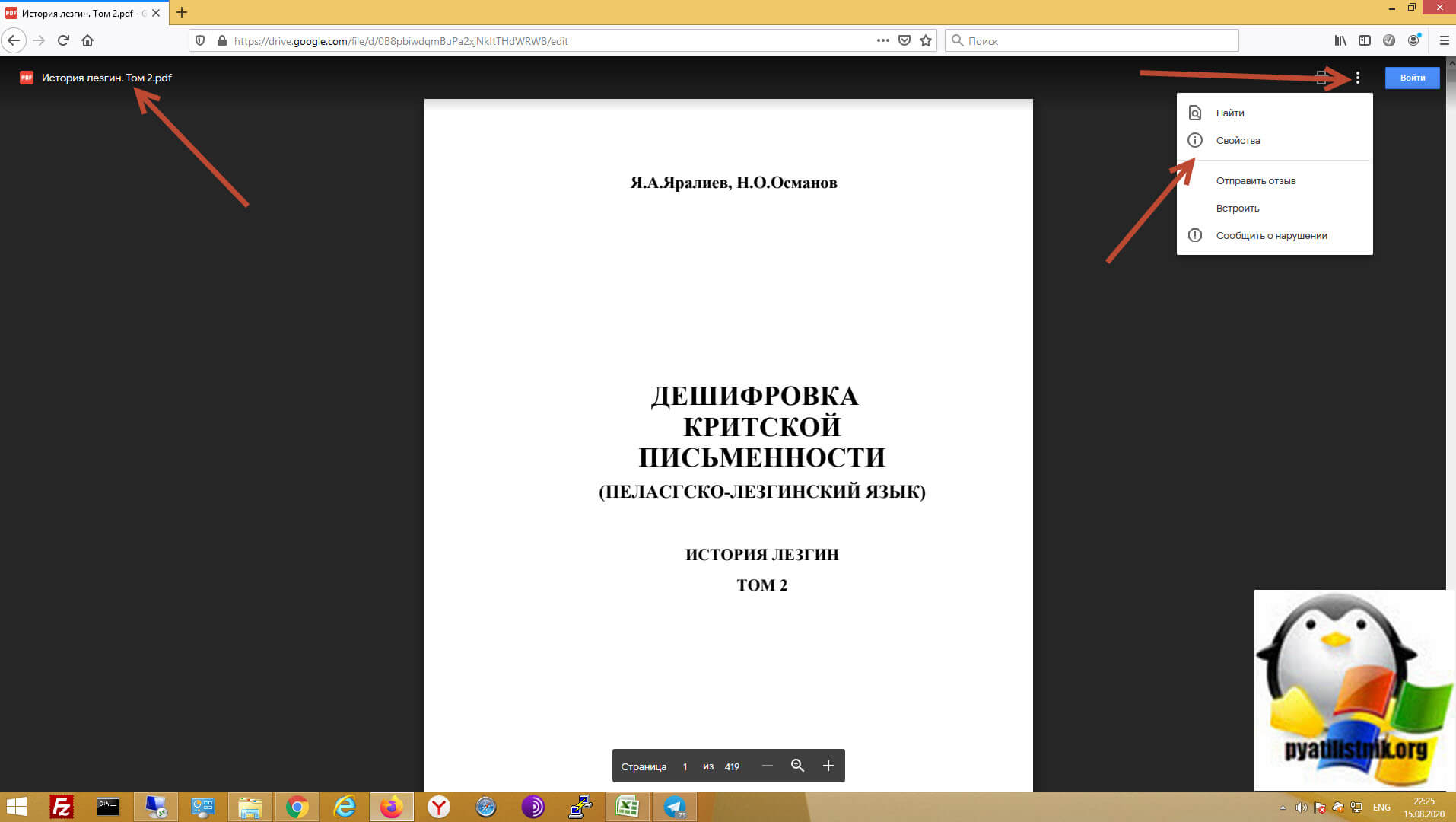
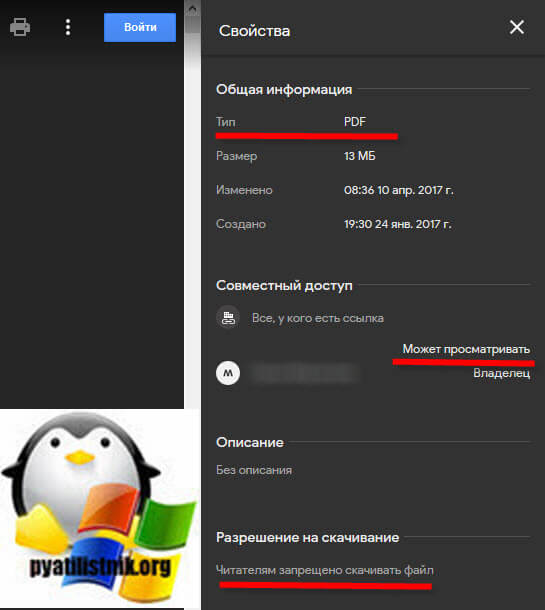
Как видно тип документа PDF, и вы максимум можете его просматривать, так как владелец просто запретил скачивать файл. Мы с вами научимся это обходить, так как мы уже с легкостью умеем скачивать ограниченное видео с Google диска, методология будет похожа, но не полностью.
Суть метода по скачиванию ограниченного PDF файла на Гугл диске
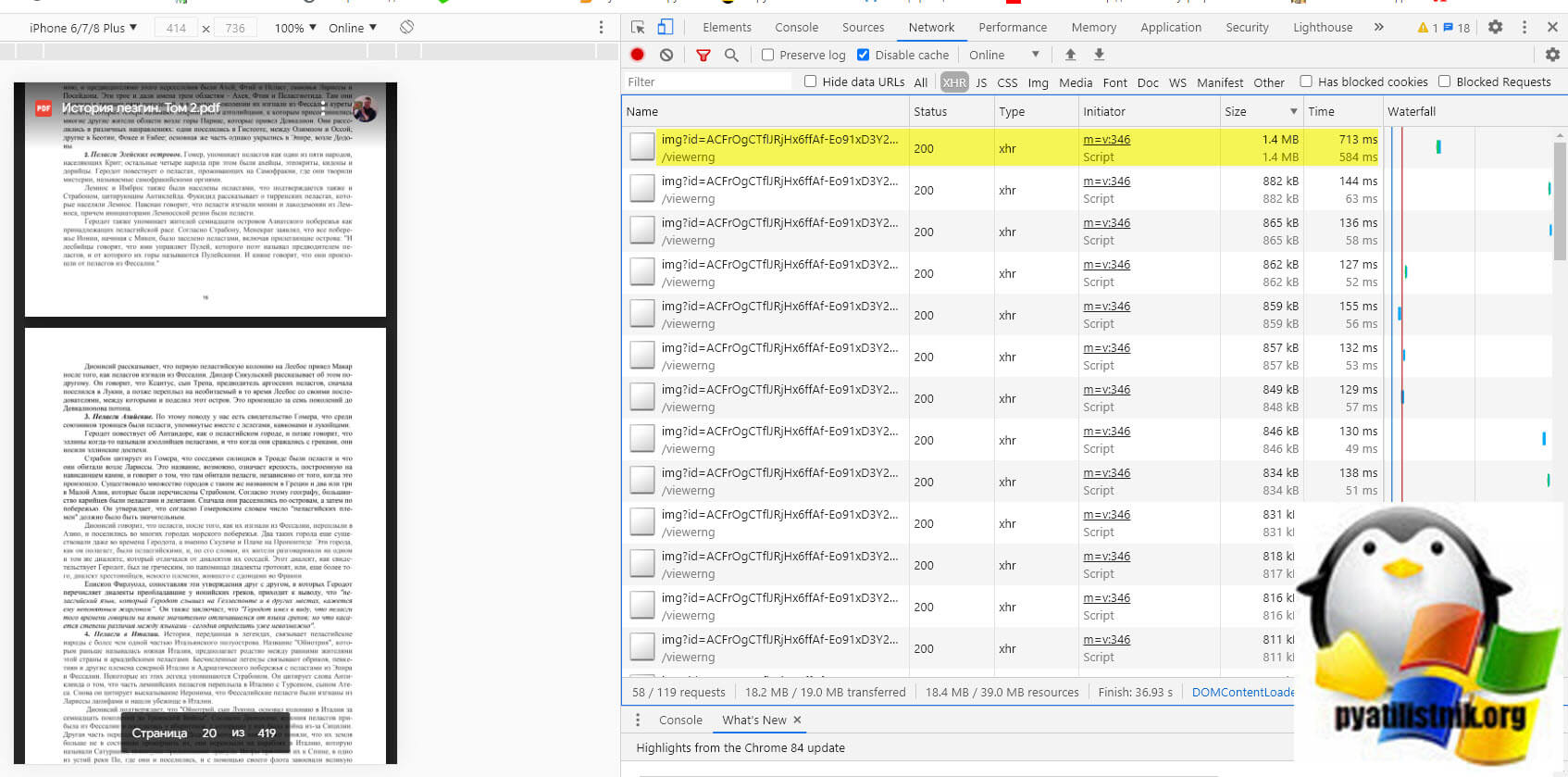
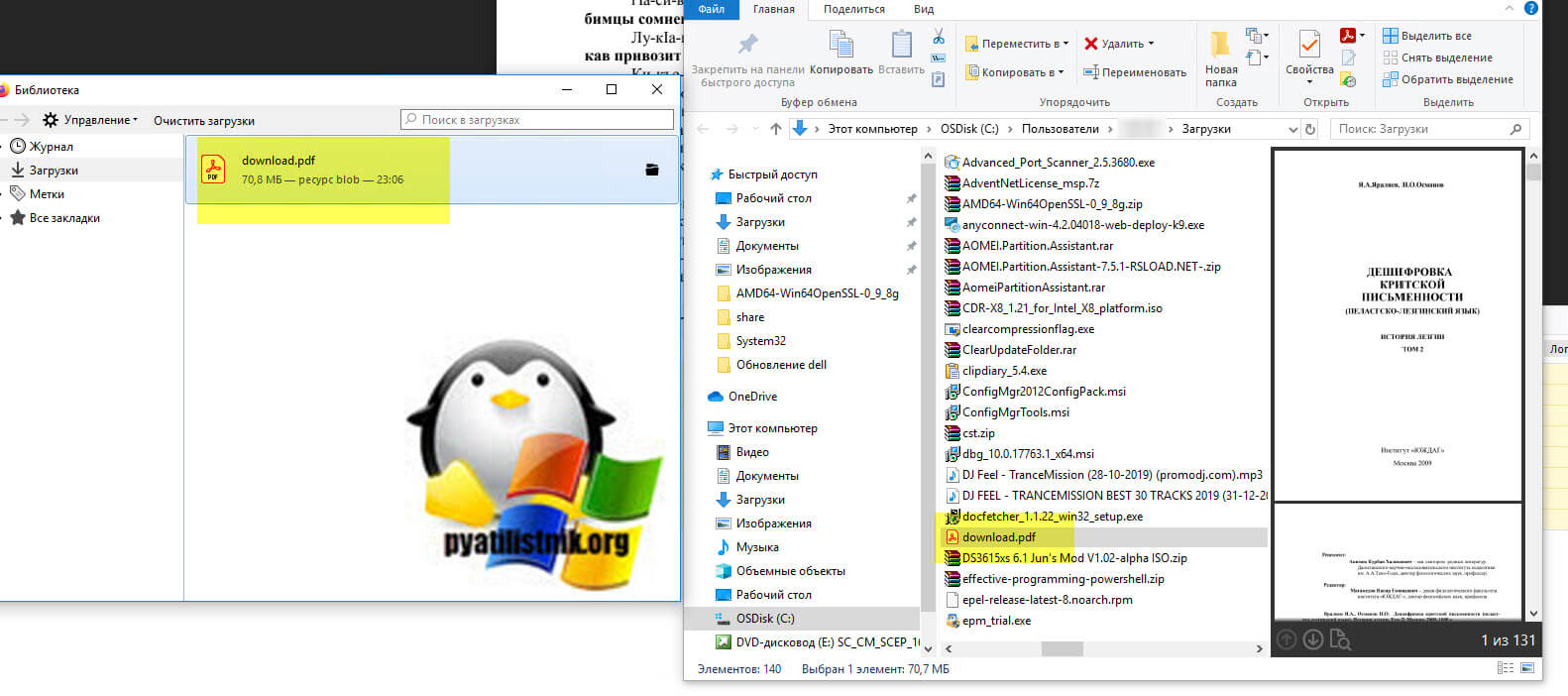
Как оказалось Гугл диск хранит все PDF файлы в виде отдельных файлов картинок и когда пользователь начинает просматривать документ, его просто собирает в веб интерфейсе, на уровне файлового хранилище, это просто картинки. Проверить это легко, вы должны открыть защищенный PDF документ, вызвать режим разработчика, через клавишу "F11" и перейдя на вкладку "Network", где после чего нужно обновить страницу с файлом. Делается это через клавишу "F5". Теперь если вы зайдете в раздел "XHR", то увидите там кучу ссылок типа "xhr". Открыв любую из них вас перекинет на страницу, которую вы уже успели промотать в книжке.
Теперь, что мы делаем поэтапно:
- Откройте ваш защищенный PDF документ, я покажу, как это делается в Mozilla Firefox и Google Chrome
- Перейдите в режим разработчика
- Нажмите клавишу F5 для обновления страницы
- Полностью пролистайте весь PDF документ, все страницы. Так как они должны попасть в локальный кэш вашего браузера
- Выполните специальный код, который объединит все страницы в кэше в единый PDF файл и позволит его загрузить на компьютер
Текст кода для скачивания защищенного PDF файла с Google Диска
jspdf.onload = function () {
let pdf = new jsPDF();
let elements = document.getElementsByTagName("img");
for (let i in elements) {
let img = elements[i];
console.log("add img ", img);
if (!/^blob:/.test(img.src)) {
console.log("invalid src");
continue;
}
let can = document.createElement('canvas');
let con = can.getContext("2d");
can.width = img.width;
can.height = img.height;
con.drawImage(img, 0, 0, img.width, img.height);
let imgData = can.toDataURL("image/jpeg", 1.0);
pdf.addImage(imgData, 'JPEG', 0, 0);
pdf.addPage();
}
pdf.save("download.pdf");
};
jspdf.src = 'https://cdnjs.cloudflare.com/ajax/libs/jspdf/1.5.3/jspdf.debug.js';
document.body.appendChild(jspdf);
Как загрузить ограниченный PDF из Google Drive через Mozilla
- Откройте ваш защищенный PDF документ, я покажу, как это делается в Mozilla Firefox
- Перейдите в режим разработчика. В Mozilla Firefox это делается, через одновременное нажатие клавиш CTRL+Shift+I или вызов соответствующего меню "Веб разработка - Инструменты разработчика"

- Далее нажмите клавишу F5 и обновите страницу
- Полностью, по порядку пролистайте все страницы данного PDF файла
Перейдите на вкладку "Консоль". Именно сюда нам нужно будет вставлять код, но по умолчанию политика безопасности Mozilla Firefox запрещает выполнение неподписанных скриптов. Чтобы это обойти вам нужно, это разрешить.
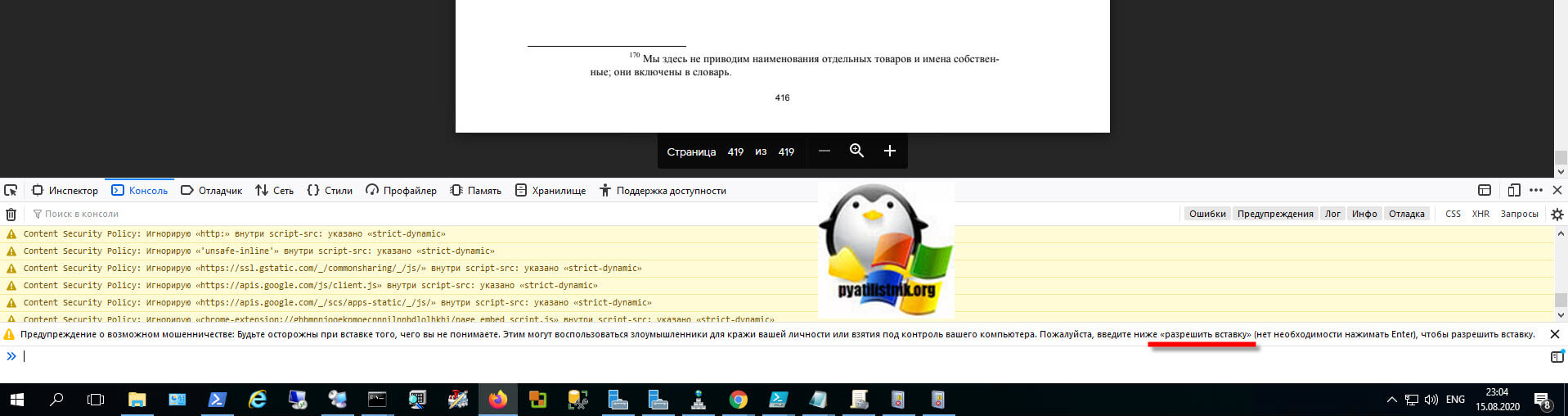
Вам нужно ввести "разрешить вставку" и нажать Enter.
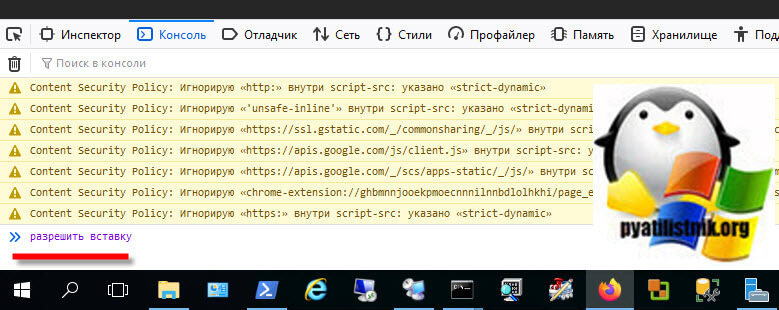
Теперь вставляем код. Для его выполнения нажмите одновременно CTRL и Enter.
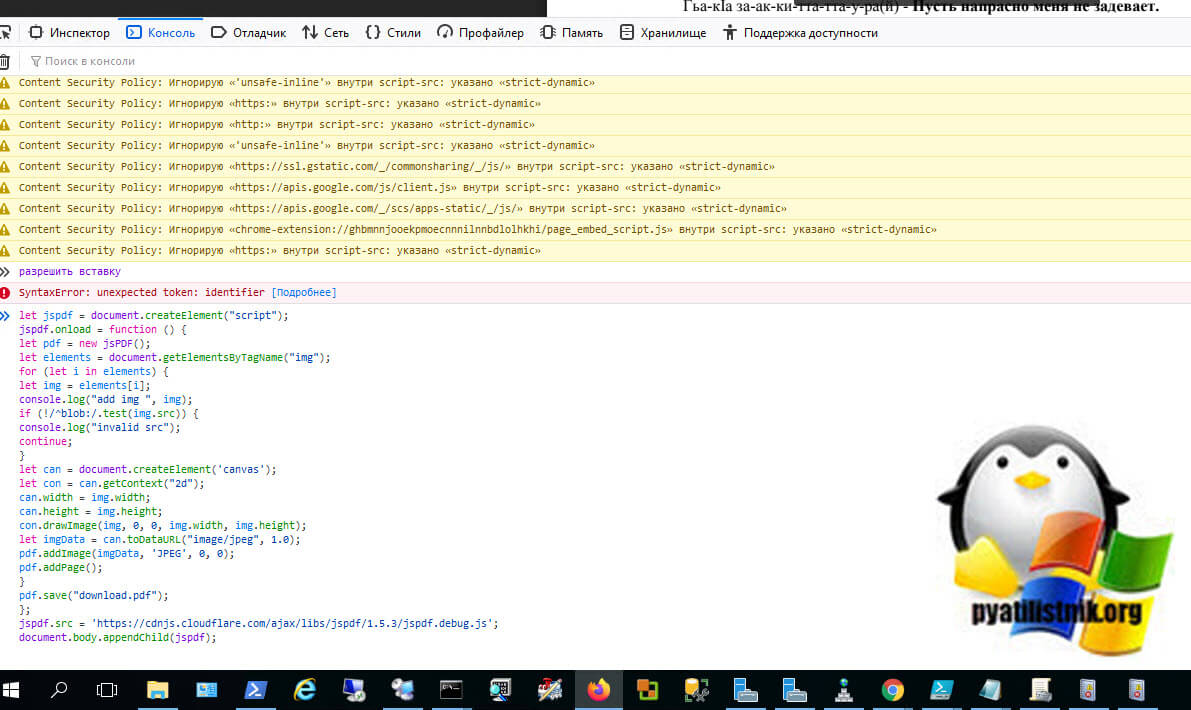
Начинается процесс скачивания картинок и объединение их в единый PDF-файл.
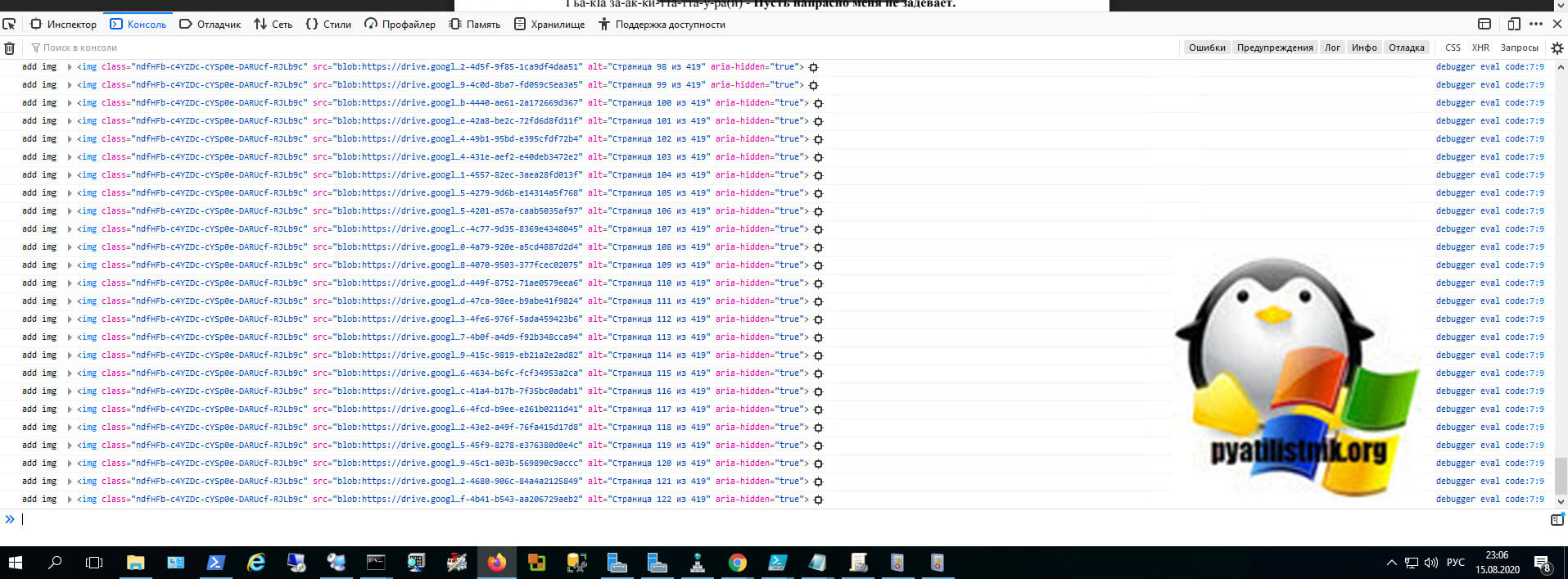
Через некоторое время браузер вам предложит сохранить DPF файл к вам на компьютер.
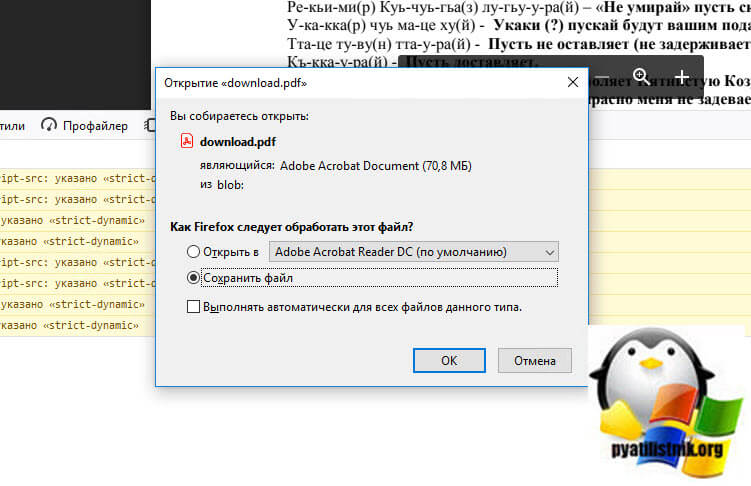
Как видите я успешно загрузил ограниченный владельцем PDF документ, все прекрасно работает.
Как загрузить ограниченный PDF из Google Drive через Chrome
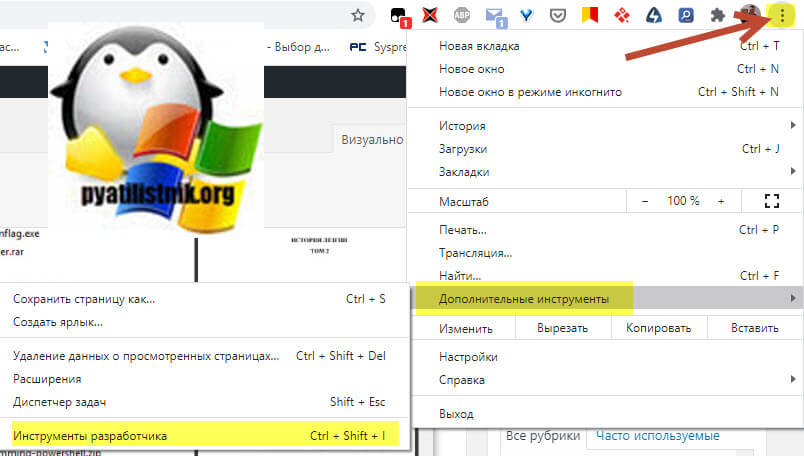
- Откройте ваш защищенный PDF документ, я покажу, как это делается в Google Chrome
- Перейдите в режим разработчика. В Google Chrome это делается, через нажатие клавиши F11 или вызов соответствующего меню "Дополнительные - Инструменты разработчика (CTRL+SHOFT+I)"
- Обязательно выберите режим iPad Pro для максимального разрешения и выставите масштаб 100%, в противном случае вы скачаете документ не с очень хорошим качеством. Далее нажмите клавишу F5 и обновите страницу
- Полностью, по порядку пролистайте все страницы данного PDF файла
- Далее перейдите на вкладку "Console"
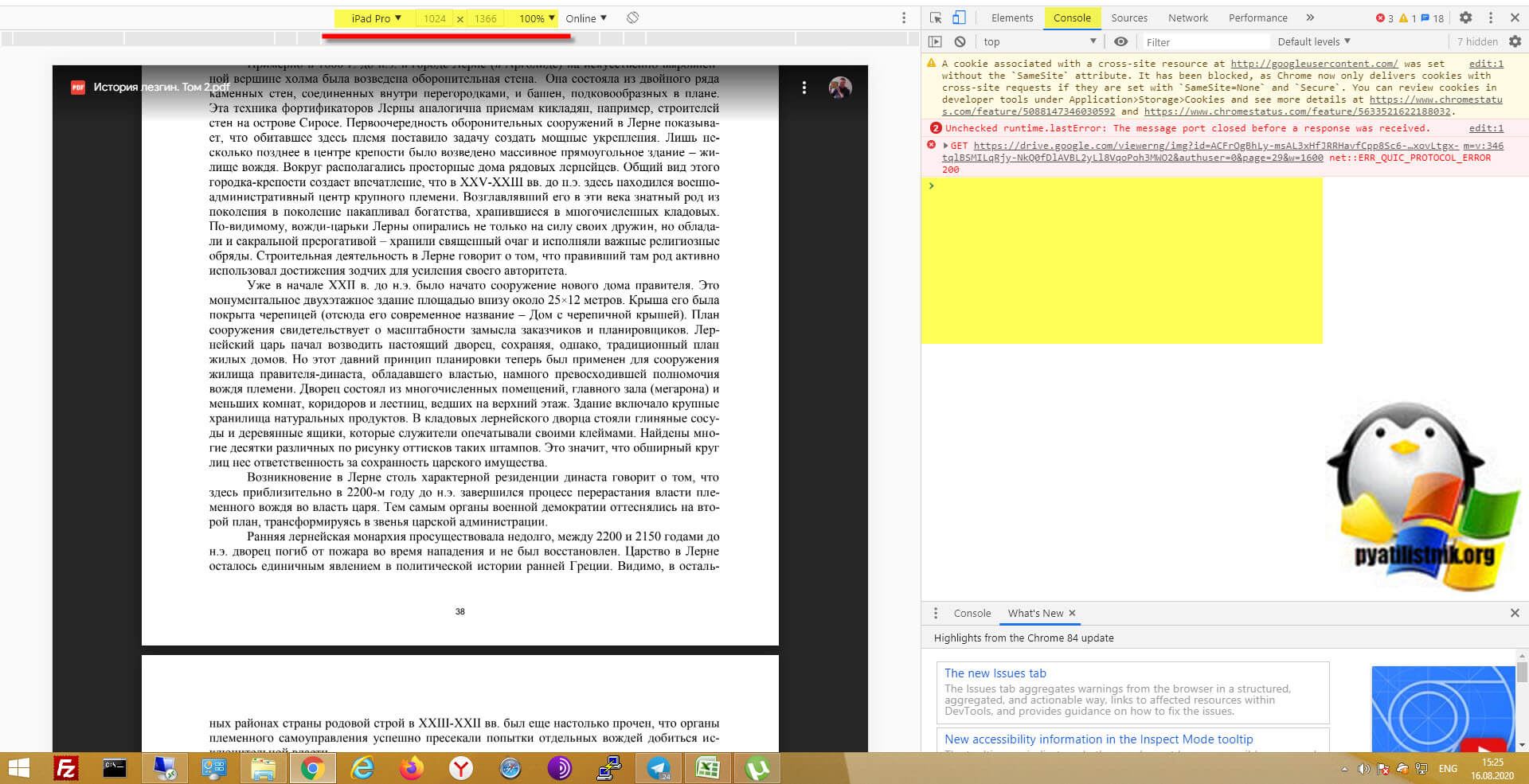
Вам необходимо вставить представленный выше код для скачивания ограниченного PDF файла, после чего просто нажать Enter.
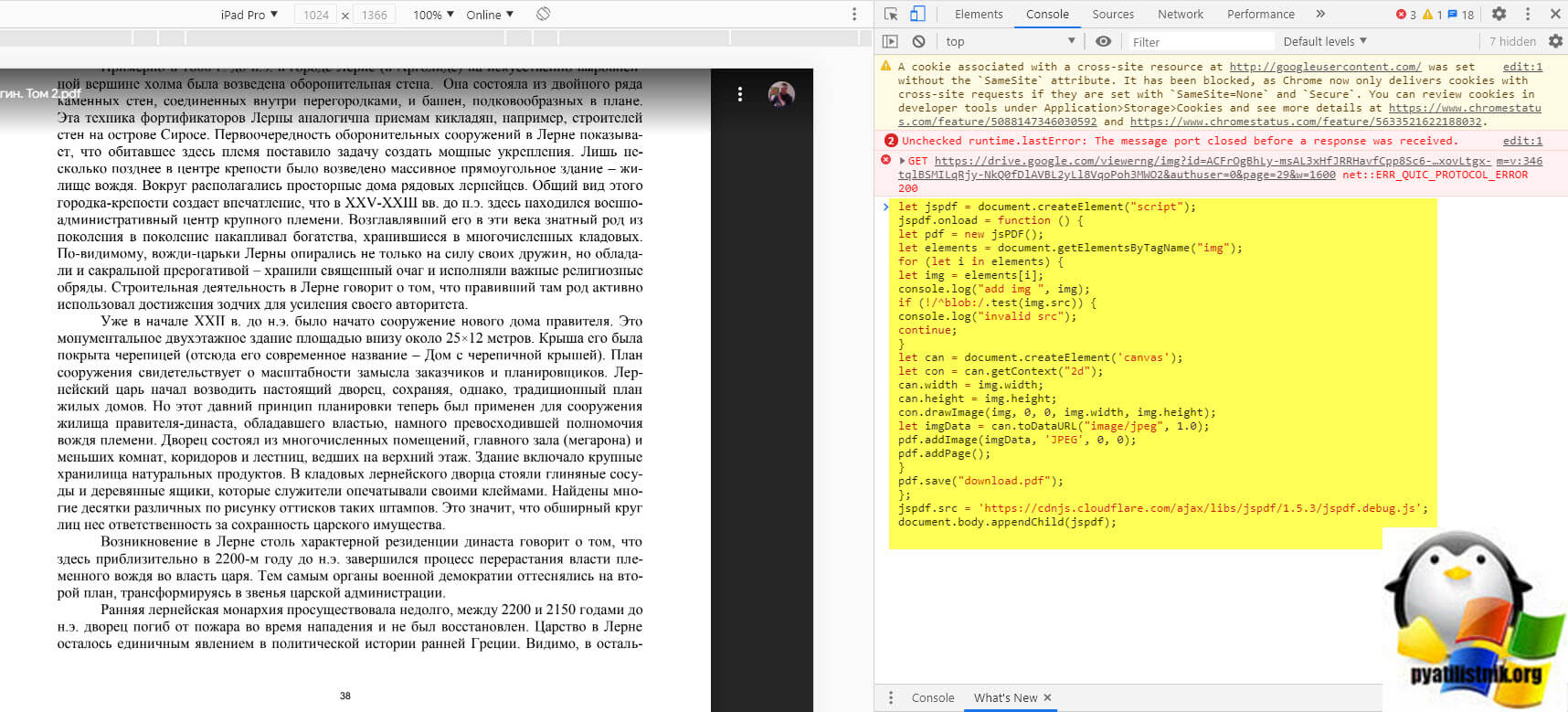
Начнется процесс сборки вашего PDF документа.
Через пару мгновений вы получите нужный вам PDF документ.
Обновление скрипта от 22.11.2024
За обновленный скрипт, спасибо подписчику Игорю.
// Создаём Trusted Types Policy (если используется Trusted Types)
const policy = trustedTypes.createPolicy(‘default’, {
createScriptURL: (url) => url
});// Создаём элемент для загрузки библиотеки jsPDF
let jspdf = document.createElement(«script»);// Указываем безопасный (TrustedScriptURL) источник для
jspdf.src = policy.createScriptURL(‘https://cdnjs.cloudflare.com/ajax/libs/jspdf/1.5.3/jspdf.debug.js’);// Когда библиотека загружена, выполняем основную логику
jspdf.onload = function () {
let pdf = new jsPDF(); // Создаём новый PDF-документ
let elements = document.getElementsByTagName(«img»); // Находим все на страницеfor (let i = 0; i < elements.length; i++) {
let img = elements[i];
console.log("Processing image: ", img);// Проверяем, чтобы источник изображения начинался с "blob:"
if (!/^blob:/.test(img.src)) {
console.log("Skipping invalid src: ", img.src);
continue;
}// Создаём для преобразования изображения
let can = document.createElement(«canvas»);
let con = can.getContext(«2d»);
can.width = img.width;
can.height = img.height;
con.drawImage(img, 0, 0, img.width, img.height);// Преобразуем изображение в формат Base64
let imgData = can.toDataURL(«image/jpeg», 1.0);// Добавляем изображение в PDF
pdf.addImage(imgData, ‘JPEG’, 0, 0);// Добавляем новую страницу только если это не последнее изображение
if (i 1) {
pdf.deletePage(totalPages); // Удаляем последнюю страницу
}// Сохраняем PDF с именем «download.pdf»
pdf.save(«download.pdf»);
};// Добавляем на страницу
document.body.appendChild(jspdf);
Что делать если не работает в Chrome
Тут я посоветую использовать Mozilla или же найдите версию Chrome до 100-110, главное у них отключить обновление, как вариант можно сделать из них и портативные версии.
На этом у меня все, скачивание ограниченных файлов с гугл диска через другие браузеры очень похоже, поэтому я не буду их описывать. С вами был Иван Семин, автор и создатель IT портала Pyatilistnik.org.




Очень хочется узнать как таким образом можно скачать презентацию а не pdf документ? В презентации есть много картинок+видео и текст
А это вызов, с вас пример ссылки
Спасибо большое!
Спасибо, очень круто, только не много качество хуже становиться
Просто шик, спасибо за подробную инструкцию! Очень пригодилось и заняло несколько минут. Качество на уровне.
все сделала по инструкции, файл сохраняется в плохом качестве в левом углу на листе, что то с кодом не так?
Увеличьте размер документа, поставьте 100-120%
Да ты неимоверно крут! Готов перечислить даже малость денег
Если хотите задонатить, то на странице об авторе есть реквизиты!
А ты хороший человек!!!)))
Хочется скачать вот такой документ
_ttps://docs.google.com/spreadsheets/u/0/d/1XMyVTv5hb9-nJZhHmHASHEyFDfpDneSfqu—mSlqJcU/htmlview#
Это гугл-таблицы. Возможно ли?
Нет не получиться, тут нет прав на это
Когда файл сохраняется, по низу обрезается 30% информации, по тексту это 4 строчки. От чего метод становится не рабочим, т.к. суть теряется на первом листе.
у меня такого нет, книжка скачивается на ура
У меня не получается — я вижу XHR — отдельные страницы, образуется
download.pdf — но он пустой — 1 страница пустая
Google Chrome ubuntu 20.04
Да скрипт запускается в Tampermonkey — привязанного к веб странице с книжкой в момент refresh.
add img 0
VM1068 userscript.html:24 invalid src
VM1068 userscript.html:22 add img ƒ item() { [native code] }
VM1068 userscript.html:24 invalid src
VM1068 userscript.html:22 add img ƒ namedItem() { [native code] }
VM1068 userscript.html:24
add img 0
VM943 userscript.html:24 invalid src
VM943 userscript.html:22 add img ƒ item() { [native code] }
VM943 userscript.html:24 invalid src
VM943 userscript.html:22 add img ƒ namedItem() { [native code] }
VM943 userscript.html:24 invalid src
Navigated to _ttps://drive.google.com/file/d/0B5yKZ3bWyNe6SHB2T1BHYVdsT1k/view
VM1027 userscript.html:22 add img 0
VM1027 userscript.html:24
Получилось — но после некоторых усилий. На ubuntu 20.04 — у меня не работает из GOOGLE CHROME но работает из CHROMIUM и MOZILLA. Скрипт надо каждый раз руками копировать открыв инструменты разработчика и закладку консоль. Там нет надписи paste если правую кнопку мыши жать. Надо скопировать просто скрипт левой кнопкой мыши и нажать на среднюю — и RETURN. Ну конечно предварителино освежив, пролистав, перед этим настроив размер ctrl++. (извиняюсь за занудство).
Гениально просто!
И работает! Спасибо.
Виноват! Адрес страницы не гугл диск.
Доброго времени суток. Вопрос : а есть ли скрипт , чтобы проделать ту же операцию , только с дропбокс … тоже стоит запрет на скачивание и запрет на печать… а страниц много 150+ (я их вижу по отдельности и даже номера есть… но как их в кучку собрать и автоматически ? )
Подставлял ваш скрипт — выдает ошибку : мол дропбоксом запрещено использовать скрипты или чтото такое.
Refused to load the script ‘(тут ваш скрипт) ‘ because it violates the following Content Security Policy directive: «script-src ‘unsafe-eval'(и далее ссылки видимо на правила сервиса)
Для стандартной ориентации страниц работает супер! А для альбомной не получается ((( — обрезает.
Добрый день. А как excel файл скачать?
Тоже вопрос какую функцию в код добавить, что бы альбомная ориентация получилась пдф при скачивании
для альбомной ориентации ребят:
pdf.addPage(», ‘landscape’);
Вот это нужно вставить вместо
pdf.addPage();
Спасибо большое очень помог
не получается альбомный лист ввести pdf.addPage(», ‘landscape’); ошибка((
если вводить как вы писали(с книжным вариантом) все получается.
Спасибо
Спасибо за статью! Очень полезно.
Есть еще вызов для Вас.
А можно сделать тоже самое, но для произвольного сайта? Чтобы скрипт сохранял все закешированные картинки при том, что они закачиваются не в виде BLOB, а в виде обычных файлов. Например, запускаем скрипт через консоль для новостного сайта и получаем все картинки со страницы. Сейчас скрипт работает только с гугл документами, а если запустить его на другом сайте, то сформируется пустой документ.
И второе, тоже очень важное. Можно картинки не собирать в единый PDF, а сохранить в исходном виде (JPG) отдельным файлами и без запроса на сохранение каждого файла?
Поясню для чего это нужно. Есть защищенный онлайн просмотрщик документов, в котором сделано все, чтобы пользователь не мог скачать просматриваемый материал. Смотреть можно, скачать нет. Но, по сути, этот сервис работает точно также, как и сервис гугла из Вашей статьи. При каждом нажатии на кнопку “следующая страница”, подгружается отдельная картинка и используется кеширование. Названия картинок и адреса меняются при каждой загрузке и состоят из сотни символов. Угадать адрес картинки не получается. Можно уже загруженные картинки скачивать из кэша. Вручную я из кэша картинки смог вытащить. Но нужно как-то автоматизировать процесс. В одном документе может быть 1000 страниц. А таких документов может быть много. Сами скачанные картинки удобней хранить отдельными файлами, чтобы их можно было переименовывать, пересылать, раскладывать по папочкам итп. При этом важно сохранить очерёдность скачивания файлов и при сохранении желательно называть их 0001, 0002, 0003 итп.
Адрес для тестирования есть, но я его не хочу публиковать в открытом доступе. Если сделать универсальный скрипт для сохранения картинок произвольного сайта, то и для своей задачи я его смогу адаптировать. Некоторый опыт в программировании есть, но на других языках.
Я пробовал решить задачу без скриптов, с помощью утилиты просмотра кэша браузера (MZCacheView). Частично работает, но не так как надо. Копировать выбранные файлы получается. Но утилита не умеет их в нужном порядке сохранять в папку, а это важно. Оригинальные названия файлов состоят из сотен символов. Утилита обрезает название файла до какой-то длинны. У них получается одинаковое называние и тогда каждому файлу добавляется числовой индекс. Вроде бы так и надо. Но проблема в том, что файлы сохраняются в последовательности по времени закачки с точностью до секунды. В одну секунду может быть закачано несколько файлов и в результате внутри каждого секундного интервала последовательность сохраненных файлов сбивается на произвольную.
спасибо!!!
Всё получилось, огромное спасибо!!!
Четко и быстро расписана методика , рекомендую!
Скачал пдф файл но он идет картинками не могу скопировать текст, как это исправить?
Не совсем понятно, что именно за проблема опишите подробнее или сделайте скриншот
При увеличении качество текста отличное, но режет картинку, в зависимости от приближения, иногда даже пополам( А без увеличения нормально, но качество не очень… Что посоветуете?
Даже не знаю, скиньте ссылку попробую посмотреть
Спасибо! Всё отлично скачалось на Гугл Хроме! Правда мне пришлось размер исходного файла на сайте поставить на 100%, иначе более крупный размер после сохранения урезается по краям. Качество сохранённого файла очень хорошее. Чёткость картинок и текст смотрибельно/читабельно. 🙂
Где и как выбрать качество iPad Pro?
Как скачать XLS файл ?
подскажите, как скачать docx?
Пример приведите попробую
уииии, спасибо!!!!! Так просто!!!)))) Немного с отображением больших картинок помучалась,но все получилось!!!!
Спасибо большое очень помогли!
Благодарю, работает при масштабе 100%, больше — соответственно обрезает.
Но при 100% читается.
у меня получилось скачать качественно pdf в альбомной ориентации при такой строчке кода —
let pdf = new jsPDF(«l», «mm», «a3»);
Вопрос владелец видит, кто у него все таки скачал файл?
Нет
здравствуйте. У меня альбомный pdf файл. Скачивает его наполовину обрезанным, пробовала ваш код и правки которые люди советовали в комментариях. С вашим кодом — скачивает обрезанным. Если вставлять правки — вообще ошибку выдает. В чем может быть дело?
Здравствуйте! Такая же проблема, как у Марии. Скачивается обрезанным, если альбомная ориентация и требуется приближение, так как требуется хорошее качество. Правки из комментов тоже не помогают.
Если не приближать, нормально скачивается, но очень некачественно.
КАЙФ!!!!!
Спасибо тебе мил человек! Дай Бог здоровья и денег побольше.
Здравствуйте, умоляю Вас, помогите пожалуйста!
Если вас не затруднит, подскажите, каким образом можно скачать защищенный docs. файл или хотя бы скопировать текст? Т.Т
сам файл лежит в «гугл документах», вот ссылка:
_ttps://docs.google.com/document/d/1WauyboAQIE0mC1iUAcpHKXKd3AT64XV6nKntchGLaXw/edit
Вероника, вот инструкция, как это сделать
у меня качество получилось хуже, чем на скриншоте.Если увеличивать масштаб, то скачивается только видимая на экране часть страницы/ Причем, в мозилле скрипт вообще не заработал, только в Опере.
Попробовал данный способ в отношении файла на _docs.google.com
К сожалению не сработал — файл сохраняет, но это одностраничный пустой pdf файл.
Будем искать…
для альбомного размера достаточно изменить вначале
let pdf = new jsPDF();
на
let pdf = new jsPDF(‘landscape’, ‘pt’, ‘a4’);
Если разобраться, то в этом примере выкачивается не сам PDF-файл, а сканы всех его страниц, в том виде, как их генерирует браузер. И текст, который можно было выделить при просмотре оригинала перестает быть текстом и становится картинкой.
Так что если хочется сохранить именно текст, то CTRL+S и скачиваем именно веб-страницу, из которой потом можно надергать текст. Что бы не пользоваться различными распознователями текста.
Добрый день, спасибо все получилось. Однако файл хотелось бы скачать в альбомном формате. Советы комментаторов не помогают или я не правильно и не туда из ввожу. Может кто то может поделится отдельным скриптом на вертикальные листы?
Добрый день. Спасибо большое! Все получилось. Для личной домашней печати сойдет.
Спасибо!
Добрый день!
А как насчет смешанных страниц А4 и А3
Пожалуйста, помогите перевернуть станицы горизонтально. У меня не выходит((((
Все советы из комментариев перепробовала, не исключаю то дело во мне
Красаавчик, человечище!
Но, нужно повер поинт еще….
Спасибо огромное! Получилось с первого раза!
Новый скрипт, который сам подбирает масштаб и ориентацию, сам скроллит перед скачиванием, сохраняет файл в максимальном качестве. Не увеличивайте масштаб браузера больше 150%, скрипт не сработает
let jspdf = document.createElement(«script»);
jspdf.onload = function () {
let pdfDocumentName = «Document»;
let doc;
function generatePDF (){
let imgTags = document.getElementsByTagName(«img»);
let checkURLString = «blob:https://drive.google.com/«;
let validImgTagCounter = 0;
for (i = 0; i img.naturalHeight){
//console.log(«Landscape»);
orientation = «l»;
//ratio = img.naturalWidth/img.naturalHeight
}else {
//console.log(«Portrait»);
orientation = «p»;
//ratio = img.naturalWidth/img.naturalHeight
}
let scalefactor = 1.335;
let pageWidth = img.naturalWidth * scalefactor;
let pageHeight = img.naturalHeight * scalefactor;
//let imagexLeft = (pageWidth — img.naturalWidth)/2;
//let imagexTop = (pageHeight — img.naturalHeight)/2;
if (validImgTagCounter === 1){
doc = new jsPDF({
orientation: orientation,
unit: «px»,
format: [pageWidth, pageHeight],
});
doc.addImage(imgDataURL, «PNG», 0, 0, img.naturalWidth, img.naturalHeight);
}else{
doc.addPage([pageWidth, pageHeight] , orientation);
doc.addImage(imgDataURL, «PNG», 0, 0, img.naturalWidth, img.naturalHeight);
}
}
}
pdfDocumentName = pdfDocumentName + «.pdf»;
doc.save(pdfDocumentName);
}
let allElements = document.querySelectorAll(«*»);
let chosenElement;
let heightOfScrollableElement = 0;
for (i = 0; i =allElements[i].clientHeight){
if (heightOfScrollableElement chosenElement.clientHeight){
console.log(«Auto Scroll»);
let scrollDistance = Math.round(chosenElement.clientHeight/2);
//console.log(«scrollHeight: » + chosenElement.scrollHeight);
//console.log(«scrollDistance: » + scrollDistance);
let loopCounter = 0;
function myLoop(remainingHeightToScroll, scrollToLocation) {
loopCounter = loopCounter+1;
console.log(loopCounter);
setTimeout(function() {
if (remainingHeightToScroll === 0){
scrollToLocation = scrollDistance;
chosenElement.scrollTo(0, scrollToLocation);
remainingHeightToScroll = chosenElement.scrollHeight — scrollDistance;
}else{
scrollToLocation = scrollToLocation + scrollDistance ;
chosenElement.scrollTo(0, scrollToLocation);
remainingHeightToScroll = remainingHeightToScroll — scrollDistance;
}
if (remainingHeightToScroll >= chosenElement.clientHeight){
myLoop(remainingHeightToScroll, scrollToLocation)
}else{
setTimeout(function() {
generatePDF();
}, 1500)
}
}, 500)
}
myLoop(0, 0);
}else{
console.log(«No Scroll»);
setTimeout(function() {
generatePDF();
}, 1500)
}
};
jspdf.src = ‘https://cdnjs.cloudflare.com/ajax/libs/jspdf/1.5.3/jspdf.debug.js’;
document.body.appendChild(jspdf);
Спасибо! Получилось не с первого раза. По сему совет всем чайникам, как и я, внимательно смотрите Видео-инструкцию. При копировании вызывайте контекстное меню правой кнопкой мыши и там нажмите Копировать. У меня при использовании Кнтрол+с, фишка не срабатывала. Всем удачи!
Есть ли такая инструкция для яндекс диска? По аналогии ничего не выходит, скачивается пустой одностраничный pdf
Кошмар( полдня ковыряюсь с этой инструкцией, либо не влезает на лист, либо вся скомканная в углу листа, и не прочесть. Как просто вытащить эти изображения из «блоба»? ПДФку я потом и так могу сделать.
Здравствуйте. К сожалению, нельзя скачать файл((( он как сохраняется в формате ПДФ, но не открывается (только через браузер), так и после всех ваших манипуляций сохраняется как даунлод пдф, но открывается так же, только через браузер(((( Памамгити….
Огромная, просто нереальная благодарность за рабочий инструмент!
Uncaught SyntaxError: unexpected token: identifier
Вот такая запись выходит, когда нажимаю на Enter
Что делать дальше?
Добрый день, при попытке скачивания вылетает эта ошибка «This document requires ‘TrustedScriptURL’ assignment»
Это как-то можно обойти?
Заранее спасибо за ответ
Спасибо.
Пользуюсь уже несколько недель.
Только теперь в Mozilla приходится печатать
разрешить вставку;
Иначе не срабатывает
Раньше работал. Теперь не работает что-то изменилась походу. Можете помочь ???
Попробуйте с Mozilla
Гениально!!!. Дай Бог тебе здоровья, выручил оч. сильно. Правда в Гугле не получилось, пришлось Мозилу ставить. Правда при нормальном качестве правый край документа был слегка обрезан, не все было видно. При худшем качестве все вошло. Но все же читать можно. Еще раз спасибо
Добрый день! Ранее скрипт работал, сейчас не удается скачать файл. Выдает
This document requires ‘TrustedScriptURL’ assignment.
Uncaught TypeError: Failed to set the ‘src’ property on ‘HTMLScriptElement’: This document requires ‘TrustedScriptURL’ assignment.
Попробуйте выполнить в Mozilla
огромная благодарность за скрипт. все сработало, но только в FireFox
Спасибо! Это а потрясающе, вы меня сильно выручили
Дай вам Бог здоровья, добрый человек. Что бы я без вас делала…))
В Хроме не сработало, установила Мозиллу и все прошло как по маслу.
доброго дня.
ошибка вышла
VM 641:23 Uncaught TypeError: Failed to set the ‘src’ property on ‘HTMLScriptElement’: This document requires ‘TrustedScriptURL’ assignment.
Спасибо, очень выручили.
VM818:23 This document requires ‘TrustedScriptURL’ assignment. а если такое что делать?
Спасибо за скрипт! Я попробовал в google chrome — сейчас уже не работает. Нужно было сначало в консоль ввести команду: allow pasting
А потом вставлять скрипт. Я скрипт исправил с помощью ИИ:
// Создаём Trusted Types Policy (если используется Trusted Types)
const policy = trustedTypes.createPolicy(‘default’, {
createScriptURL: (url) => url
});
// Создаём элемент для загрузки библиотеки jsPDF
let jspdf = document.createElement(«script»);
// Указываем безопасный (TrustedScriptURL) источник для
jspdf.src = policy.createScriptURL(‘https://cdnjs.cloudflare.com/ajax/libs/jspdf/1.5.3/jspdf.debug.js’);
// Когда библиотека загружена, выполняем основную логику
jspdf.onload = function () {
let pdf = new jsPDF(); // Создаём новый PDF-документ
let elements = document.getElementsByTagName(«img»); // Находим все на странице
for (let i = 0; i < elements.length; i++) {
let img = elements[i];
console.log("Processing image: ", img);
// Проверяем, чтобы источник изображения начинался с "blob:"
if (!/^blob:/.test(img.src)) {
console.log("Skipping invalid src: ", img.src);
continue;
}
// Создаём для преобразования изображения
let can = document.createElement(«canvas»);
let con = can.getContext(«2d»);
can.width = img.width;
can.height = img.height;
con.drawImage(img, 0, 0, img.width, img.height);
// Преобразуем изображение в формат Base64
let imgData = can.toDataURL(«image/jpeg», 1.0);
// Добавляем изображение в PDF
pdf.addImage(imgData, ‘JPEG’, 0, 0);
// Добавляем новую страницу только если это не последнее изображение
if (i 1) {
pdf.deletePage(totalPages); // Удаляем последнюю страницу
}
// Сохраняем PDF с именем «download.pdf»
pdf.save(«download.pdf»);
};
// Добавляем на страницу
document.body.appendChild(jspdf);
К сожалению, не работает.
0. «allow pasting» и «разрешить вставку» делал.
1. В Mozilla пишет «Uncaught SyntaxError: illegal character U+2018» на код от 22.11.2024. А на старый код генерирует 1 пустой лист.
2. В chrome на новый код пишет «Uncaught SyntaxError: Invalid or unexpected token»
Помогите пожалуйста.
Исправленный код, который работает через консоль Google Chrome
// Создаём Trusted Types Policy (если используется Trusted Types)
const policy = trustedTypes.createPolicy(‘default’, {
createScriptURL: (url) => url
});
// Создаём элемент для загрузки библиотеки jsPDF
let jspdf = document.createElement(«script»);
// Указываем безопасный (TrustedScriptURL) источник для jsPDF
jspdf.src = policy.createScriptURL(‘https://cdnjs.cloudflare.com/ajax/libs/jspdf/1.5.3/jspdf.debug.js’);
// Когда библиотека загружена, выполняем основную логику
jspdf.onload = function () {
let pdf = new jsPDF(); // Создаём новый PDF-документ
let elements = document.getElementsByTagName(«img»); // Находим все изображения на странице
for (let i = 0; i < elements.length; i++) {
let img = elements[i];
console.log("Processing image:", img);
// Проверяем, что источник изображения начинается с "blob:"
if (!/^blob:/.test(img.src)) {
console.log("Skipping invalid src:", img.src);
continue;
}
// Создаём canvas для преобразования изображения
let can = document.createElement("canvas");
let con = can.getContext("2d");
can.width = img.width;
can.height = img.height;
con.drawImage(img, 0, 0, img.width, img.height);
// Преобразуем в DataURL (Base64)
let imgData = can.toDataURL("image/jpeg", 1.0);
// Добавляем изображение в PDF
pdf.addImage(imgData, "JPEG", 0, 0);
// Добавляем новую страницу, если это не последний элемент
if (i < elements.length — 1) {
pdf.addPage();
}
}
// Сохраняем PDF с именем "download.pdf"
pdf.save("download.pdf");
};
// Добавляем скрипт на страницу (подгрузка jsPDF)
document.body.appendChild(jspdf);
Uncaught SyntaxError: Invalid or unexpected token
Вот какая ошибка, помогите пожалуйста