
Что такое HA Admission control в ESXI 5.x.x
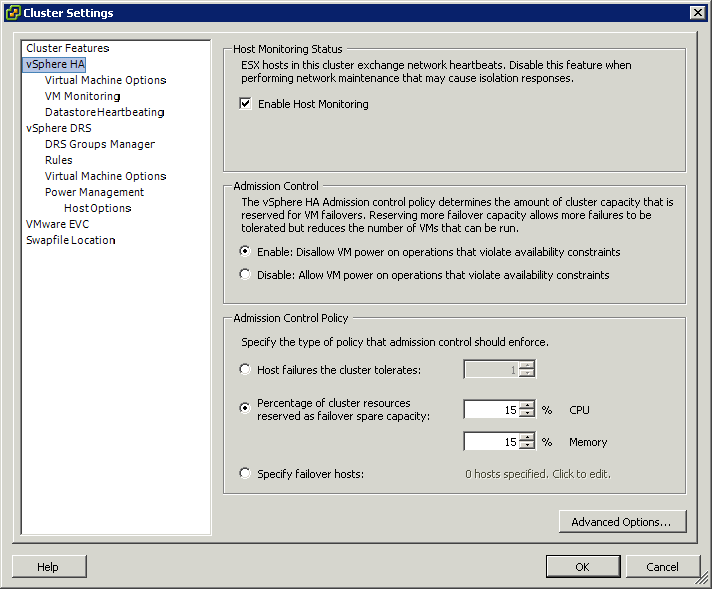
Конспект по принципам работы HA admission control.
Почти все, что нужно знать об admission control, умещается в одном предложении:
vCenter Server использует admission control, чтобы обеспечить достаточное количество ресурсов для отказоустойчивости и выполнения требований резервирования ресурсов.
Это утверждение делится на две задачи для admission control:
- обеспечить достаточное количество ресурсов на случай сбоя;
- обеспечить соблюдение резервирования ресурсов для виртуальных машин (CPU reservations, memory reservations).
Т.о. admittion control - это резервирование ресурсов, а не управление ими.
При расчетах admission control учитывает только включенные виртуальные машины и активные хосты.
Admission control имеет три политики, каждая из которых по разному резервирует ресурсы кластера:
1. Host failures the cluster tolerates;
2. Percentage of cluster resorces reserved as failover spare capacity;
3. Specify failover hosts.
Политика Specify failover hosts наиболее проста для понимания. Она позволяет определить хост, который будет использоваться в случае сбоя. Этот хост будет стоять и ждать своего часа. Простой оборудования - основной минус этой политики.
Две другие политики рассчитывают резервы на отказоустойчивость, исходя в основном из значений резервов CPU и памяти, выставленных на включенных виртуальных машинах.
Политика Host failures the cluster tolerates (количество сбоев хостов, на которое рассчитан кластер) ведет расчет ресурсов с помощью так называемых слотов и учитывает наихудший сценарий событий. Слот состоит из двух компонентов:
- Memory slot (слот памяти);
- CPU slot (слот CPU).
При расчете слота памяти учитывается включенная виртуальная машина в кластере, которая имеет самый большой резерв памяти, и ее overhead. Размер слота памяти равен memory overhead + memory rezervation.
Размер слота CPU определяется по наибольшему значению резерва CPU для включенной виртуальной машины, либо берется значение по умолчанию 32MHz для vSphere 5.0, 256MHz для более ранних версий.
Разделив общее количество ресурсов на размер слота HA admission control получает количество свободных слотов. Между числом слотов памяти и числом слотов CPU выбирается наименьшее. Например, имеем 80 слотов памяти и 120 слотов CPU, значит, фактически имеем 80 слотов. Из этого числа отнимаем количество слотов на самом мощном хосте, т.к. на нем этих самых слотов помещается больше всего (т.е. потеря этого хоста - это и есть наихудший сценарий). Т.о. если у нас 5 хостов, и на каждом по 10 слотов памяти и CPU, то мы имеем не 50, а 40 слотов для работы при "Host failures the cluster tolerates" = 1.
Очевидно, что алгоритм этой политики "reservations -> slot size -> worst case" (резерв -> размер слота -> наихудший случай) очень сильно зависит от значений резервирования, выставленных на виртуальных машинах.
Политика Percentage of cluster resorces reserved as failover spare capacity дает возможность установить размер резерва ресурсов под отказоустойчивость. В vSphere 5.0 этот резерв устанавливается отдельно для памяти и CPU. В этой политике сравниваются текущее значение ресурсов, доступных для включения новых виртуальных машин (Current Failover Capacity), с заданным резервом ресурсов под отказоустойчивость (Configured Failover Capacity). Если Current меньше Configured, виртуальная машина не включится. Грубо принцип такой: если в кластере из четырех хостов Configured Failover Capacityустановлен 25%, то ресурсы, эквивалентные ресурсам одного хоста, резервируются под отказоустойчивость.
Расчеты выглядят так
Current Failover Capacity = (root resource pool - resource requirements) / root resource pool,
где
root resource pool - общее число ресурсов хостов минус расходы на гипервизор (т.е. это не все физические ресурсы хостов);
resource requirements - ресурсы, необходимые для работы включенных виртуальных машин.
Resource requirements - это сумма требований к ресурсам от каждой включенной виртаульной машины:
- для памяти: memory overhead + memory rezervation;
- для CPU берется установленный резерв либо значение по умолчанию 32MHz для vSphere 5.0, 256MHz для более ранних версий.
Например,
- кластер состоит из трех хостов по 9GHz и 24GB (расходы на гипервизор уже учтены);
- в нем 4 включенных виртуальных машины:
- VM1 использует 2GHz и 1GB (без резерва),
- VM2 использует 2GHz и 2GB (резерв 2GB),
- VM3 использует 1GHz и 2GB (резерв 2GB),
- VM4 использует 3GHz и 6GB (резерв 1GHz и 2GB);
- memory overhead для каждой виртуальной машины 100MB;
- Configured CPU Failover Capacity - 25%, Configured Memory Failover Capacity - 25%.
Получаем
root resource pool CPU = 9GHz+9GHz+9GHz = 27GHz,
root resource pool memory = 24GB+24GB+24Gb=72GB,
-
CPU resource requirements = 32MHz+32MHz+32MHz+1GHz= 1.096GHz,
Memory resource requirements = 0+100+2048+100+2048+100+2048+100= 6544MB = 6.4GB;
-
Current CPU Failover Capacity = (27GHz-1.096GHz)/27= 95.94%=96%,
Current Memoty Failover Capacity = (72GB – 6.4Gb)/72= 91%.
-
Из этих ресурсов мы можем использовать на новые виртуальные машины:
CPU = 96-25 = 71%,
Memory = 91- 25 = 66%.
Логично было бы параметры Configured Failover Capacity настраивать при изменении количества хостов в кластере.
Самой прозрачной и логичной выглядит политика Specify failover hosts. Используем ее, если не душит жаба по поводу простаивающих мощностей.
Между политиками Host failures the cluster tolerates и Percentage of cluster resorces reserved as failover spare capacity есть смысл выбрать вторую, как наиболее гибкую и простую. Собственно, из всех трех политик заокеанские гуру как правило рекомендуют выбирать Percentage of cluster resorces reserved as failover spare capacity.
Популярные Похожие записи:
 Ошибка DRS на кластере ESXI
Ошибка DRS на кластере ESXI- Не запускается файловая роль на Failover Cluster
- Ошибка Unable to apply DRS resource settings on host
- Режимы кворума отказоустойчивого кластера Windows в группах доступности AlwaysOn
- Ошибка The cluster Resource Hosting Subsystem (RHS) process was terminated and will be restarted
- Get-ClusterLog и поиск ошибок в Failover Clusters


