 Всем привет сегодня расскажу как сменить имя сервера в Windows Server 2008R2 редакции Server Core. Сперва необходимо определить текущее имя сервера:
Всем привет сегодня расскажу как сменить имя сервера в Windows Server 2008R2 редакции Server Core. Сперва необходимо определить текущее имя сервера:C:>hostname WIN-2Z78XR56TIW
 Всем привет сегодня расскажу как сменить имя сервера в Windows Server 2008R2 редакции Server Core. Сперва необходимо определить текущее имя сервера:
Всем привет сегодня расскажу как сменить имя сервера в Windows Server 2008R2 редакции Server Core. Сперва необходимо определить текущее имя сервера: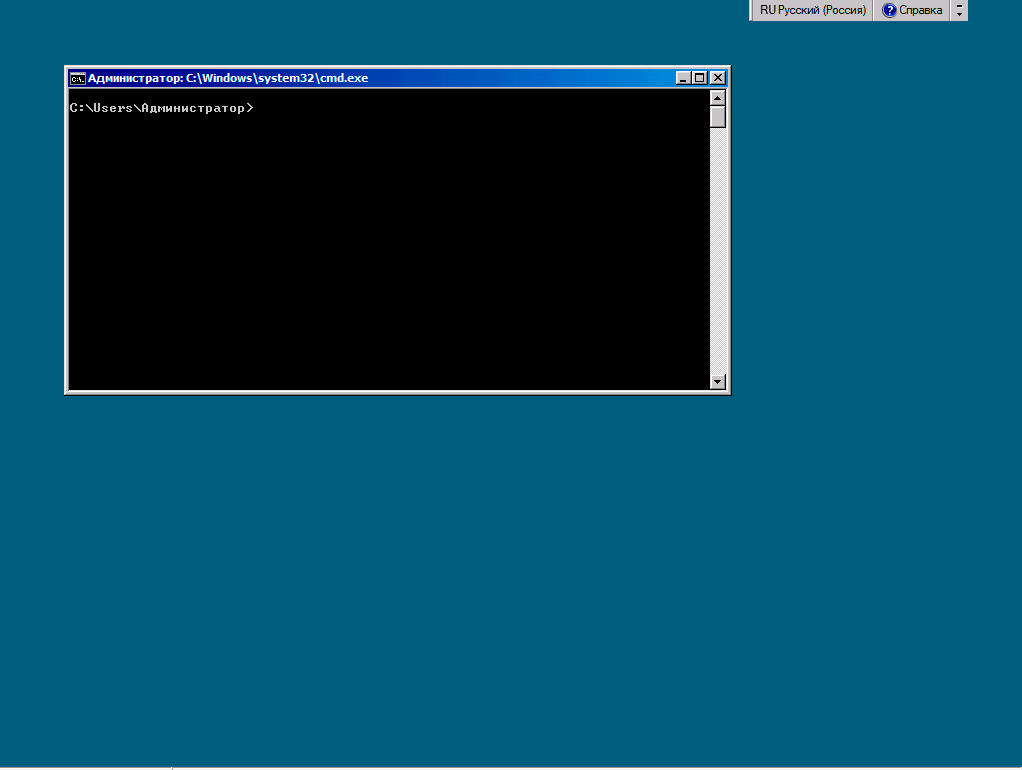 Всем привет сегодня расскажу как ввести в домен Windows Serve 2008R2 и Windows Server 2012R2 в режиме Server Core. Напоминаю, что у данной версии нету графического интерфейса, и поэтому выполнить поставленную задачу можно. только через командную строку. Ранее мы с вами развернули Active Directory и разобрали как ввести компьютер в домен. Введем наш сервер с именем Core в домен contoso.com, используя доменную учетную запись admin, которую мы создавали до этого:
Всем привет сегодня расскажу как ввести в домен Windows Serve 2008R2 и Windows Server 2012R2 в режиме Server Core. Напоминаю, что у данной версии нету графического интерфейса, и поэтому выполнить поставленную задачу можно. только через командную строку. Ранее мы с вами развернули Active Directory и разобрали как ввести компьютер в домен. Введем наш сервер с именем Core в домен contoso.com, используя доменную учетную запись admin, которую мы создавали до этого: Все привет сегодня расскажу про утилиту RunAs для безопасного удаленного администрирования Windows. Одна из самых непротиворечивых концепций безопасности гласит, что без крайней необходимости работать под учетной записью администратора не следует. Особенно под учетной записью администратора домена. Однако, решение административных задач, требующих повышенных привилегий, эта концепция не отменяет. Удаленный доступ к серверу через Remote Desktop – это лишние телодвижения, да и, опять же, небезопасно. Наиболее подходящий путь – локальный запуск нужных оснасток управления с использованием команды RunAs, которая позволяет администратору выполнять любые задачи в системе, зарегистрировавшись в ней с использованием учетной записи рядового пользователя.
Все привет сегодня расскажу про утилиту RunAs для безопасного удаленного администрирования Windows. Одна из самых непротиворечивых концепций безопасности гласит, что без крайней необходимости работать под учетной записью администратора не следует. Особенно под учетной записью администратора домена. Однако, решение административных задач, требующих повышенных привилегий, эта концепция не отменяет. Удаленный доступ к серверу через Remote Desktop – это лишние телодвижения, да и, опять же, небезопасно. Наиболее подходящий путь – локальный запуск нужных оснасток управления с использованием команды RunAs, которая позволяет администратору выполнять любые задачи в системе, зарегистрировавшись в ней с использованием учетной записи рядового пользователя. Всем привет! Сегодня расскажу, как скрыть программы в списке установка и удаление программ Windows. Иногда бывает полезно скрыть программу от глаз и рук пользователя, особенно ее деинсталлятор. Это позволяет тем кому эта информация не нужна, ее и не видеть. С точки зрения безопасности это мудрое решение. Такими методами можно скрыть установленную игру, чтобы родители не видели ее на своем компьютере, а вы могли играть. Думаю, каждый найдет себе, где применить эти знания.
Всем привет! Сегодня расскажу, как скрыть программы в списке установка и удаление программ Windows. Иногда бывает полезно скрыть программу от глаз и рук пользователя, особенно ее деинсталлятор. Это позволяет тем кому эта информация не нужна, ее и не видеть. С точки зрения безопасности это мудрое решение. Такими методами можно скрыть установленную игру, чтобы родители не видели ее на своем компьютере, а вы могли играть. Думаю, каждый найдет себе, где применить эти знания. Всем привет сегодня расскажу как переименовать домашний каталог администратора в Windows. По умолчанию, для хранения профиля администратора, Windows использует директорию C:\Documents and Settings\Administrator. Стандартные процедуры обеспечения безопасности предусматривают переименование учетной записи Administrator в произвольный пользовательский вариант. Скажем, в root. Однако при смене имени пользователя, директория с его профилем не переименовывается, что создает некоторые неудобства. Это не фатально, все можно исправить руками:
Всем привет сегодня расскажу как переименовать домашний каталог администратора в Windows. По умолчанию, для хранения профиля администратора, Windows использует директорию C:\Documents and Settings\Administrator. Стандартные процедуры обеспечения безопасности предусматривают переименование учетной записи Administrator в произвольный пользовательский вариант. Скажем, в root. Однако при смене имени пользователя, директория с его профилем не переименовывается, что создает некоторые неудобства. Это не фатально, все можно исправить руками: Всем привет сегодня расскажу как восстановить объекты групповой политики по умолчанию в Windows Server 2008R2. Случается, возникает необходимость восстановить исходное состояние политик для домена и для контроллеров домена (например, настроить все заново проще, чем перестроить после предыдущего системного администратора; либо возникают ошибки при применении GPO, а RSoP не выявляет ошибочно настроенную политику). Для этого существует программа dcgpofix. При ее запуске, будут утеряны все изменения объектов групповой политики Default Domain Policy и Default Domain Controllers Policy (даже в том случае, если они были переименованы).
Всем привет сегодня расскажу как восстановить объекты групповой политики по умолчанию в Windows Server 2008R2. Случается, возникает необходимость восстановить исходное состояние политик для домена и для контроллеров домена (например, настроить все заново проще, чем перестроить после предыдущего системного администратора; либо возникают ошибки при применении GPO, а RSoP не выявляет ошибочно настроенную политику). Для этого существует программа dcgpofix. При ее запуске, будут утеряны все изменения объектов групповой политики Default Domain Policy и Default Domain Controllers Policy (даже в том случае, если они были переименованы). Всем привет! Уважаемые читатели и гости IT портала Pyatilistnik.org. В минувший раз мы вами разобрали, как сбрасывать ILO порт у HP серверов. Идем далее и сегодня расскажу, как из Windows XP Home сделать Windows XP Professional. Причем без переустановки и потери данных, так сказать метод для ленивых, да и переустановка программ, игр, перенос данных занимает много времени, которое можно использовать более продуктивно и плодотворно. Я покажу вам графические методы и с использованием PowerShell.
Всем привет! Уважаемые читатели и гости IT портала Pyatilistnik.org. В минувший раз мы вами разобрали, как сбрасывать ILO порт у HP серверов. Идем далее и сегодня расскажу, как из Windows XP Home сделать Windows XP Professional. Причем без переустановки и потери данных, так сказать метод для ленивых, да и переустановка программ, игр, перенос данных занимает много времени, которое можно использовать более продуктивно и плодотворно. Я покажу вам графические методы и с использованием PowerShell.