
Ошибка DRS на кластере ESXI

Добрый день! Уважаемые читатели и гости блога. В прошлый раз мы с вами разобрали ошибку COM Surrogate и научились ее устранять. Переходим от клиентских ошибок к серверным. Буквально вчера я на одном из кластеров ESXI обнаружил вот такое предупреждение "vSphere DRS functionality was impacted due to unhealthy state vSphere Cluster Services caused by the unavailability of vSphere Cluster Service VMs. vSphere Cluster Service VMs are required to maintain the health of vSphere DRS". Как понял оно может влиять на функционал миграции, давайте разбираться в чем было дело.
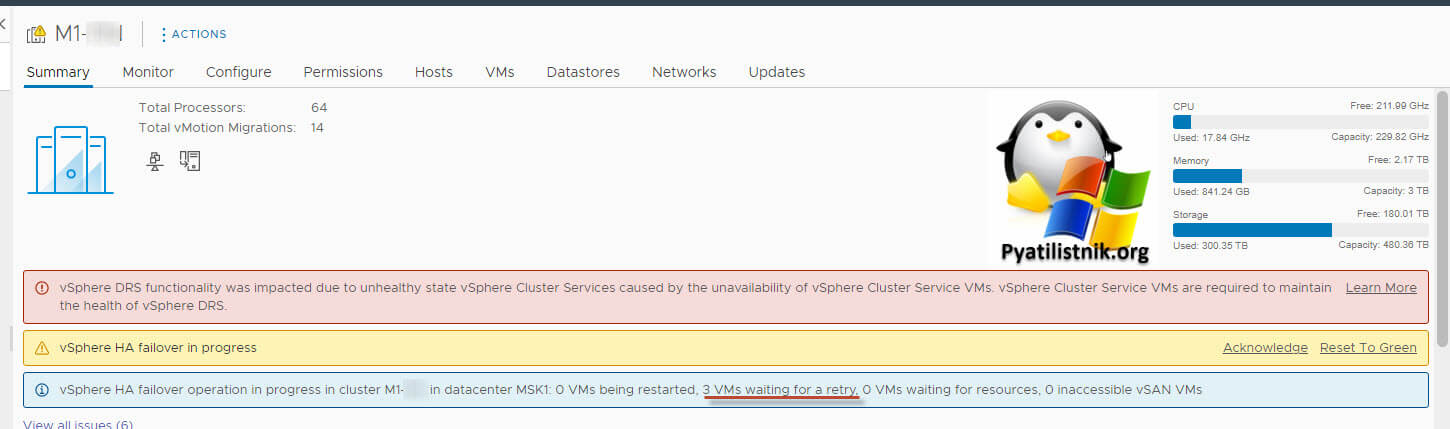
Статус на кластере "vSphere HA failover in progress"
У меня установлен vCenter 7.0.3.00100. На нем создано несколько кластеров на базе серверов Dell PowerEdge R740. На одном из таких кластеров было несколько предупреждений.
- ❌vSphere DRS functionality was impacted due to unhealthy state vSphere Cluster Services caused by the unavailability of vSphere Cluster Service VMs. vSphere Cluster Service VMs are required to maintain the health of vSphere DRS
- ❌vSphere HA failover in progress
- ❌vSphere HA failover operation in progress in cluster M1 in datacenter MSK1: 0 VMs being restarted, 3 VMs waiting for a retry, 0 VMs waiting for resources, 0 inaccessible vSAN VMs
Configuration Issue
Тут у вас сразу же будет ссылка на статью Vmware
vSphere 7.0 Update 1, vSphere DRS для кластера зависит от работоспособности vSphere Cluster Services (vCLS). vCLS в кластере настраивает кворум на системных виртуальных машинах vCLS в кластере. Эти виртуальные машины необходимы для поддержания работоспособности служб кластера. Если работоспособность vCLS пострадает из-за недоступности этих виртуальных машин в кластере, то vSphere DRS не будет работать в кластере до тех пор, пока виртуальные машины vCLS не будут восстановлены (В некоторых случаях можно мигрировать в выключенном состоянии, но бывает, что и с данной ошибкой миграция работает на работающей виртуальной машине).
Ниже перечислены операции, выполнение которых может привести к сбою, когда DRS не работает. Кроме того, следует отметить еще один момент: приведенные ниже операции в новом кластере с поддержкой DRS будут недоступны до тех пор, пока первая виртуальная машина vCLS не будет развернута и включена в этом кластере.
- Размещение/включение виртуальной машины новой рабочей нагрузки.
- Выбор хоста для виртуальной машины, которая переносится из другого кластера/хоста в vCenter.
- Перенесенная виртуальная машина может быть включена на выбранном хосте, не поддерживающем DRS.
- Перевод хоста в режим обслуживания может застрять, если на нем есть включенная виртуальная машина.
- Вызов API-интерфейсов DRS, таких как ClusterComputeResource.placeVm() и ClusterComputeResource.enterMaintenanceMode(), получит InvalidState .
- Настройка управления рабочей нагрузкой, кластера Supervisor и кластера Tanzu Kubernetes завершится неудачно.
Причина
Причиной этой ошибки может быть несколько проблем.
- Пользователь отключил или удалил виртуальные машины vCLS из кластера с поддержкой DRS.
- Не удалось развернуть виртуальные машины vCLS
- Не удалось включить виртуальные машины vCLS
- Когда vCLS отключен в кластере с использованием режима отступления
- HA не удалось выполнить аварийное переключение виртуальных машин vCLS при сбое хоста или хранилища.
Как устранить ошибку
Как я указал выше данная ошибка чаще всего связана с системными виртуальными машинами vCLS, мы из-за них в одной из статье не могли удалить датастор, получая ошибку "The resource is in use". Обратите внимание, что вам и тут подсказывают "3 VMs waiting for a retry". Если вы попытаетесь на данном кластере найти виртуальные машины vCLS, то вы их не увидите, в большинстве случаев.
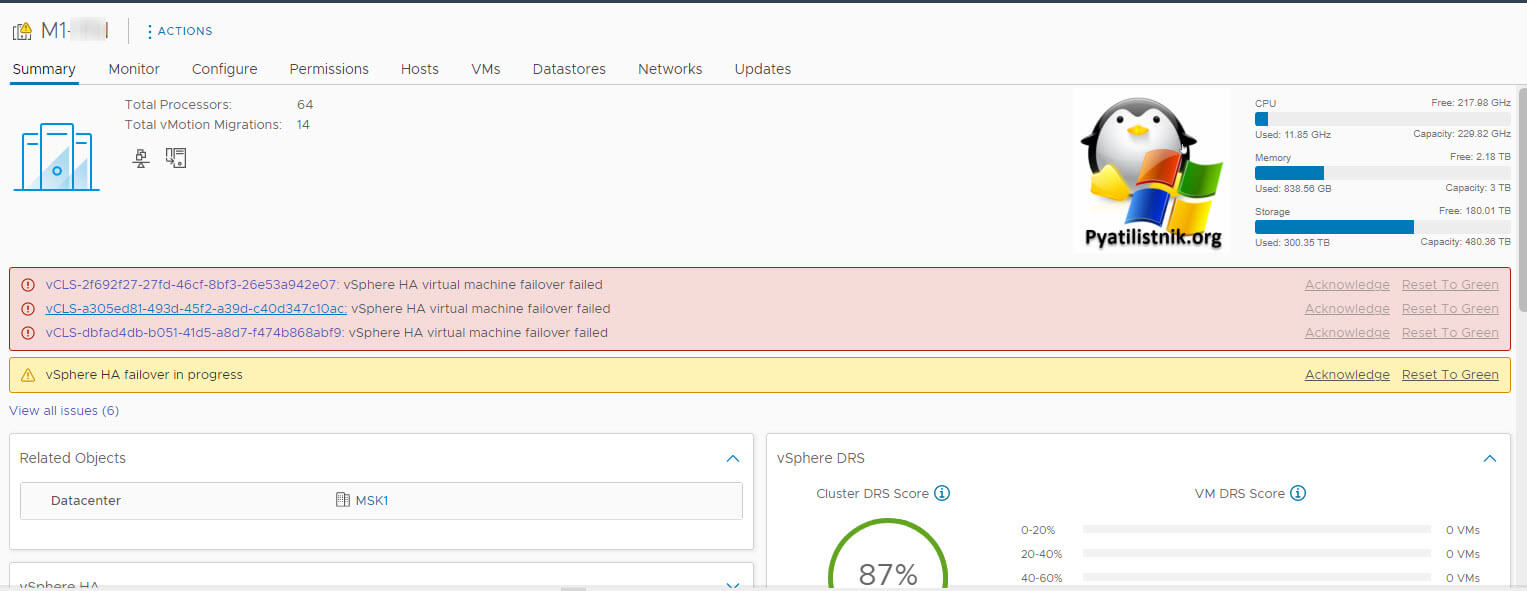
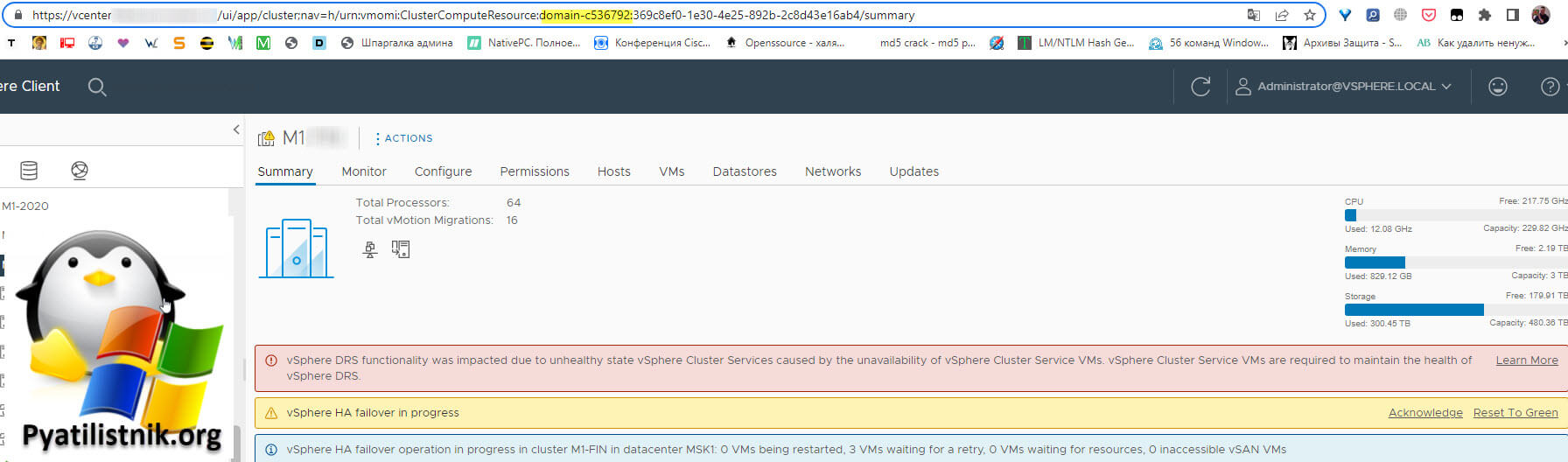
Когда я зашел из под Administrator@vsphere.local, то на данном кластере уже было больше ошибок:
Тут явно видно, что проблема с vCLS.
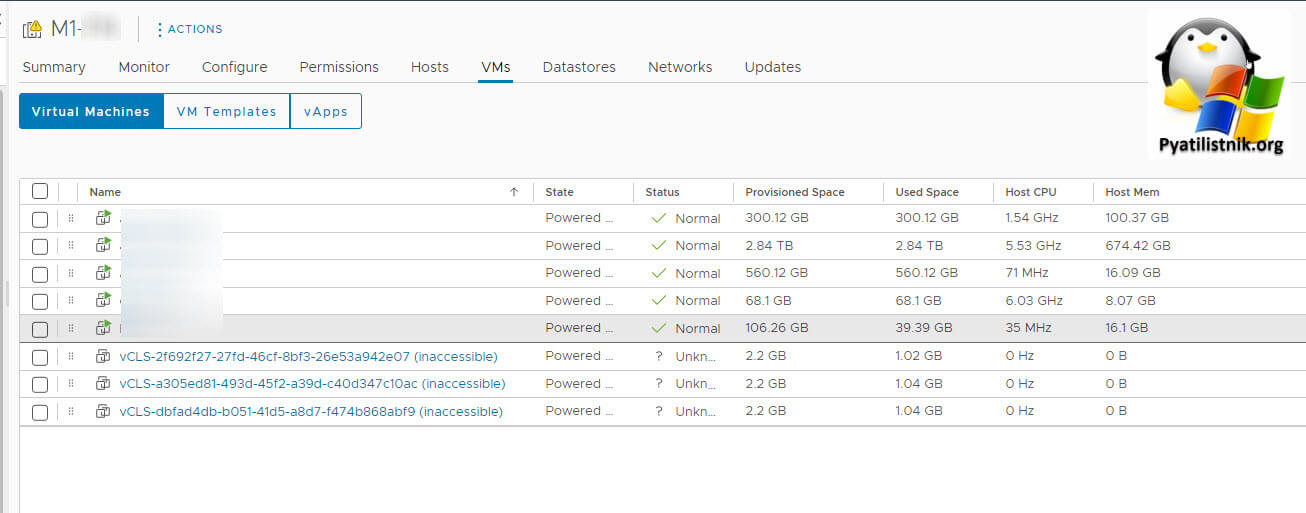
Перейдем на вкладку "VMs". Тут вы уже можете увидеть дополнительные виртуальные машины vCLS. В моем случае тут был статус (Inaccessible).
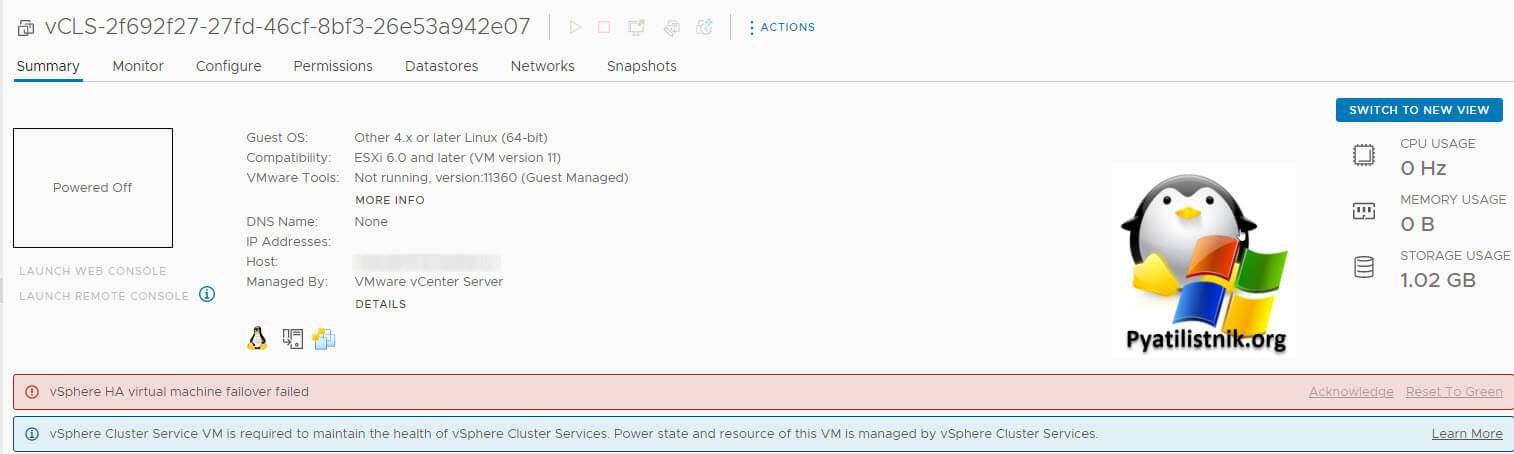
Когда вы уже перешли в объект конкретной vCLS вы так же будите наблюдать:
Как видно данная виртуалка не может запуститься:
- Недостаточно свободного ресурса в кластере. Требуется 400 МГц ЦП, 400 МБ памяти и 2 ГБ дискового пространства в кластере с более чем 3 хостами. Тут у меня этого навалом
- Ошибка общего хранилища
- Случаи потерянных виртуальных машин. Если на сервере vCenter имеются потерянные виртуальные машины vCLS из-за отключенных и повторно подключенных хостов, развертывание новых виртуальных машин vCLS в таком кластере после добавления хоста может завершиться неудачей
С ресурсами у меня все в порядке, проверяю свое хранилище. Переходим на вкладку "Datastores". Тут все стало на свои места. Данный общий диск так же имел статус (Inaccessible). Как потом выяснилось его выводил один мой коллега, и не удалил его полностью, так как что-то мешало, теперь понятно, что мешало.
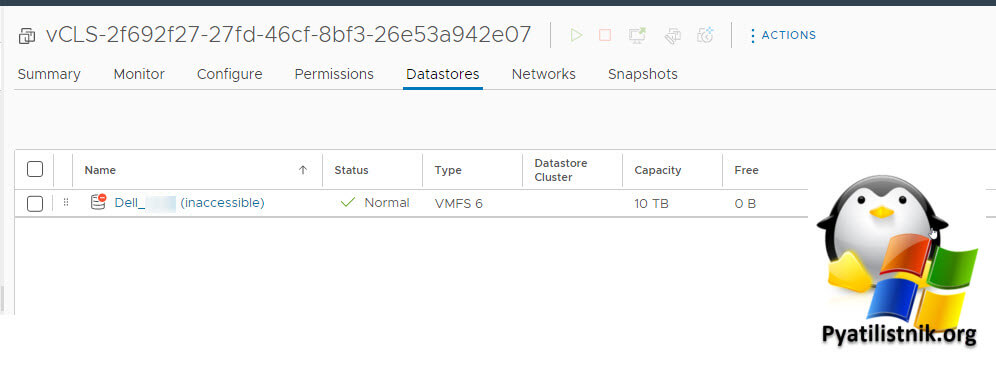
Вариантов исправления у нас несколько:
- 1️⃣Перезагрузить сервер vCenter. Не всегда на это есть возможность.
- 2️⃣Отключение режима Retreat Mode. Режим Retreat Mode в vCenter является функцией, которая позволяет автоматически восстанавливать виртуальные машины на других хостах, если текущий хост становится недоступным или неполноценным. Это позволяет обеспечить непрерывную работу виртуальных машин при возникновении сбоев или проблем с текущим хостом. При активации режима Retreat Mode vCenter автоматически переносит виртуальные машины на другие доступные хосты, чтобы минимизировать простои и снизить влияние на производительность системы.
После выключения Retreat Mode ваш vCenter сам удалит в нужном кластере виртуалки vCLS (Надо понимать, что на время у вас пропадет функционал RDS и HA). В vSphere Client выберите ваш кластер, в адресной строке у вас будет большая строка, по типу:
Вам нужно будет найти номер domain. В своем примере я его выделил.
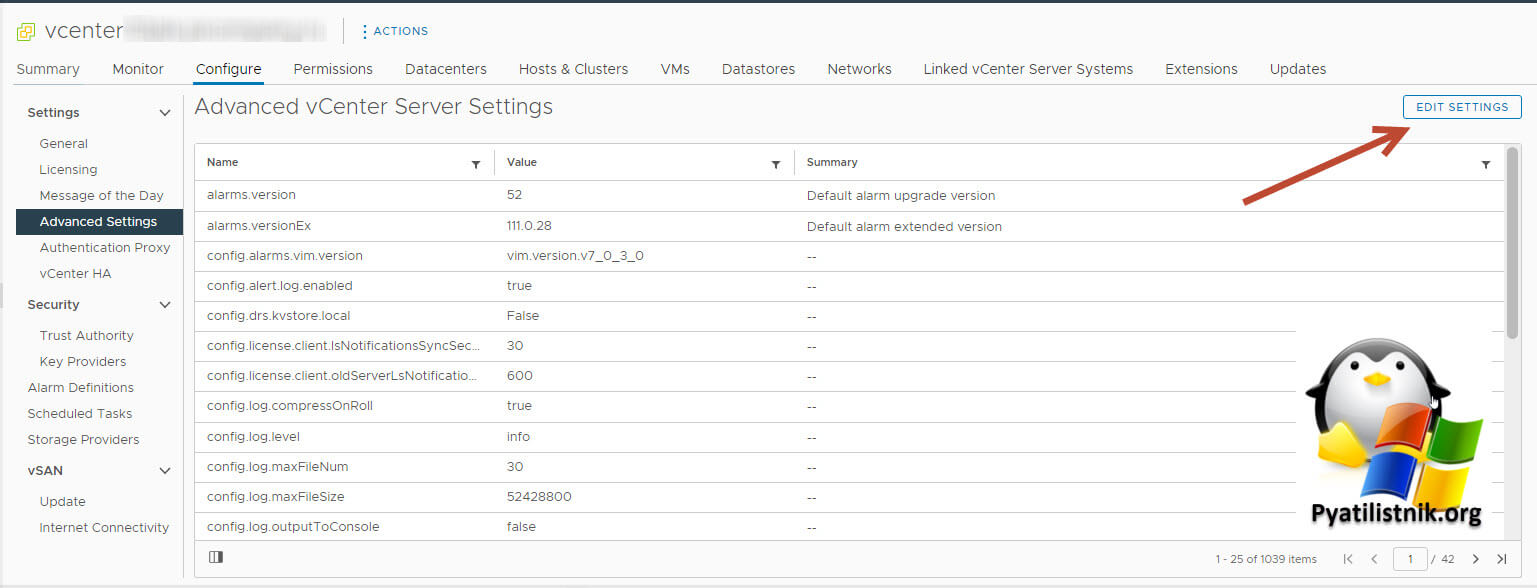
После этого переходим в самый корень vCenter. Идем в "Advanced setting - Edit settings - Edit Advanced vCenter Server Settings"
Добавляем новое значение, подставив номер кластера:
- name = config.vcls.clusters.domain-c<number>.enabled (В моем примере config.vcls.clusters.domain-c536792.enabled)
- value = False
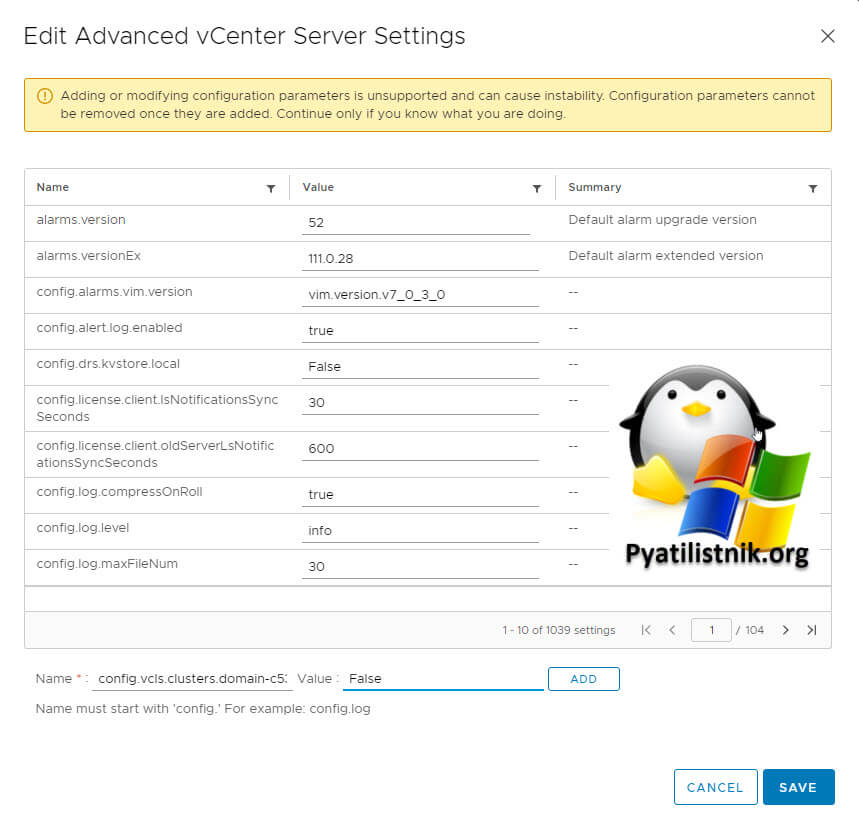
Сохраняем настройки. Служба мониторинга vCLS запускается каждые 30 секунд, поэтому примерно через 1 минуту вы увидите, что все виртуальные машины vCLS в кластере очищены. После удаления всех виртуалок vCLS можно сменить значение на True и вернуть всё как было.
- 3️⃣Выключите на время DRS на вашем кластере. Дождитесь удаления виртуалок vCLS, а затем заново включите RDS. Сделать это можно выбрав кластер, вкладка "Configure - vSphere DRS - "
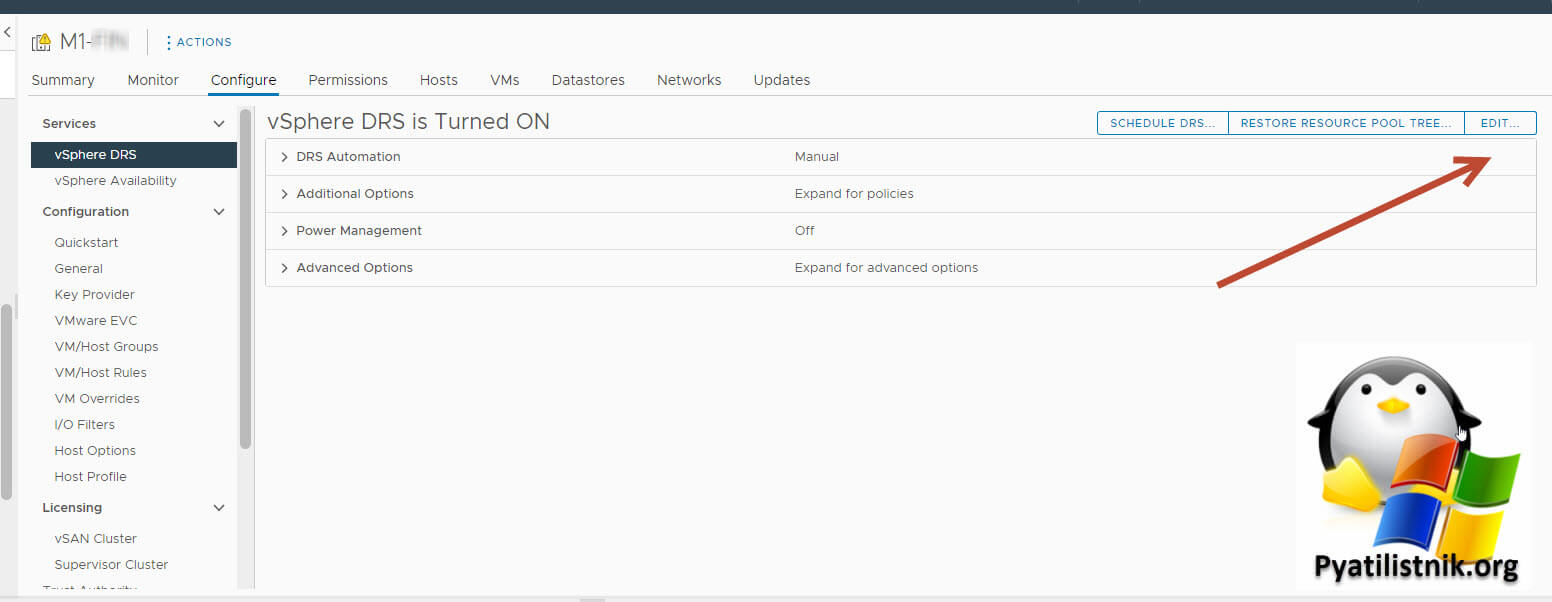
Переместите ползунок "vSphere DRS" в выключенное состояние. Потом дождитесь, что кластер удалит виртуалки vCLS. После этого заново активируем "vSphere DRS".

- 4️⃣Еще может быть ситуация, когда потребуется повторное создание сертификатов пользователей. Это решения восстановило функциональность развертывания виртуальных машин vCLS. Повторное создание сертификатов пользователей решения зависит от того, как вы обрабатываете сертификаты в vCenter. В этом случае – я думаю, это относится к большинству сред – сертификат машины был заменен сертификатом, подписанным локальным центром сертификации. Все остальные сертификаты обмену не подвергались. При такой настройке сертификаты пользователей можно легко заменить в диспетчере сертификатов .
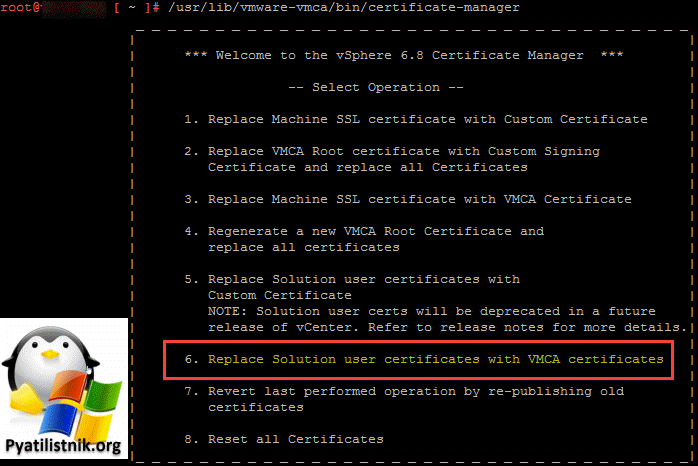
- 5️⃣Еще может быть ситуация, когда не хватает прав для пользователя VSPHERE.LOCAL\vpxd-extension-xxxx. Для того, чтобы это устранить необходимо выполнить сценарий fixAdministratorsGroup.py
Далее загрузите сценарий в каталог /tmp/vCenter. Подключитесь по SSH к vCenter, используя учетные данные root и перейдите в каталог /tmp. Сделайте скрипт как исполняемый:
Выполните следующую команду, чтобы проверить пользователей, которых необходимо удалить из группы "Администраторы".
Если будут найдены проблемы, то выполните команду:
Проверьте в vSphere Client, что включились виртуальные машины vCLS.
Дополнительные ссылки
- https://kb.vmware.com/s/article/80472
- https://communities.vmware.com/t5/VMware-vCenter-Discussions/vCLS-vm-s-are-missing-Cannot-get-them-back/td-p/2870096
- https://kb.vmware.com/s/article/79248
- https://vnote42.net/2020/04/15/replace-machine-certificate-in-vsphere-7/
- https://kb.vmware.com/s/article/2112281
- https://kb.vmware.com/s/article/88400
- https://communities.vmware.com/t5/VMware-vCenter-Discussions/vCLS-vm-s-are-missing-Cannot-get-them-back/td-p/2870096
- https://communities.vmware.com/t5/vCenter-Server-Discussions/Cluster-Agent-VM-is-missing-on-cluster-XYZ-vCLS/td-p/2808041
Популярные Похожие записи:
 Ошибка удаления диска в ESXI: The resource is in use
Ошибка удаления диска в ESXI: The resource is in use- Не запускается файловая роль на Failover Cluster
- Решено: EFI Virtual disk (0.0) Not found
- Ошибка запуска VM: File system specific implementation of Ioctl[file] failed
- Ошибка The cluster Resource Hosting Subsystem (RHS) process was terminated and will be restarted
- Кластерный диск в состоянии «Online Pending»

![Ошибка запуска VM: File system specific implementation of Ioctl[file] failed](https://pyatilistnik.org/wp-content/uploads/2023/07/file-system-specific-implementation-150x150.png "Ошибка запуска VM: File system specific implementation of Ioctl[file] failed")
