
Как организовать катастрофоустойчивую инфраструктура на базе VMware SRM-2 часть
 1 часть статьи тут
1 часть статьи тут
Почему SRM?
Главный вопрос, волнующий системных администраторов - зачем защищать виртуальные машины с помощью репликации и SRM?
Причин для использования SRM может быть несколько. Во-первых, далеко не все приложения имеют встроенные механизмы, позволяющие реализовать защиту от катастроф. В организации могут использоваться различные устаревшие или самописные, но от этого не менее критичные приложения, для которых требуется обеспечить высокую доступность.
Во-вторых, SRM обеспечивает универсальную защиту для любых сервисов, запущенных внутри виртуальных машин. Администратор виртуальной инфраструктуры в теории может и не знать, что запущено внутри: файловый сервер или СУБД Oracle, процесс настройки ВМ во всех случаях будет одинаковым.
Однако никто не требует ломать существующую работающую систему и строить все с нуля. SRM не призван заменить существующие механизмы по обеспечению катастрофоустойчивости, а лишь помочь там, где этих механизмов нет, или они труднореализуемы. Немногие инфраструктуры проектируются и развертываются с учетом отказоустойчивости. Развертывание системы, которая бы обеспечивала защиту всех сервисов, может потребовать больших финансовых и временных затрат, что вступает в диссонанс с частым требованием бизнеса предоставить рабочее решение "сейчас" (как пример: "вчера").
На первый взгляд может показаться, что отсутствие возможности автоматического переключения на резервный сайт в SRM является серьезным недостатком.
В общем случае, следует понимать, что любая автоматизация в подобном деле - это палка о двух концах. С одной стороны, вы исключаете потенциально ненадежное звено - человека, с другой - компьютер лишен творческой жилки и делает только то, что ему говорят. Настроили автоматический переезд инфраструктуры при пропадании пинга на 10 секунд, и будьте уверены - инфраструктура переедет, что бы ни случилось. С другой стороны, автоматизация может в значительной степени усложнить архитектуру решения.
Например, кластер на базе Microsoft Failover Cluster, несмотря на имеющиеся возможности по автоматизации переключения при отказе одного или нескольких узлов, требует наличия кворума - дополнительных узлов, общего диска или сетевой папки, которые придется размещать в третьем сайте для предотвращения split brain. Аналогичный пример с Microsoft SQL Server Database Mirroring, которому для автоматического переключения требуется сервер-свидетель.
Допустим, вы взвесили все "за" и "против" и для ряда приложений решили настроить защиту на уровне виртуальных машин, но пока что без SRM. Для этого вам потребуется резервный сайт с одним или несколькими серверами виртуализации, мощностей которых будет достаточно для запуска защищаемых виртуальных машин, а также СХД, куда будут реплицироваться ВМ с основного сайта. В случае катастрофы для восстановления ВМ на резервном сайте без помощи SRM администратору потребуется выполнить следующие операции:
- Получить доступ к средствам управления резервным сайтом.
- На резервной СХД остановить задания репликации, активировать реплицированные LUN'ы, презентовать их серверам виртуализации в резервном сайте.
- Из консоли управления vSphere Client переподписать и смонтировать все хранилища, расположенные на реплицированных LUN'ах.
- Зарегистрировать и добавить ВМ в нужные папки и пулы ресурсов. Подключить виртуальные сетевые адаптеры к нужным виртуальным коммутаторам.
- Запустить ВМ в заданном порядке, при необходимости, изменить настройки сетевых адаптеров.
- Проверить работоспособность ВМ.
Для небольшой компании с десятком виртуальных машин процедура восстановления может потребовать совсем немного времени. Однако, для крупной виртуальной инфраструктуры, насчитывающей множество ВМ, серверов виртуализации, виртуальных сетей, пулов ресурсов, папок каждая лишняя минута простоя может влететь в копеечку.
SRM прямо из коробки автоматизирует вышеуказанные операции и позволяет выполнять их практически без вмешательства человека, не считая задачи по нажиманию "большой" красной кнопки и финальной проверки работы ВМ, хотя они также поддаются некоторой автоматизации.
SRM позволяет реализовывать как классическую схему резервирования, включающую один основной и один резервный сайт (active-passive), так и гораздо более сложные, например, схему N+1 с несколькими активными и одним общим (shared) резервным сайтом, или схему active-active, когда оба сайта могут одновременно выполнять рабочую нагрузку и являться резервными друг для друга. Для каждого сайта (основного или резервного) требуется собственный экземпляр VMware vCenter Server.
SRM лицензируется по количеству защищаемых ВМ и доступен в двух редакциях: Standard (~195$) и Enterprise (~495$) между которыми существует ровно одно различие - максимальное количество защищаемых виртуальных машин. Для версии Standard количество защищаемых ВМ не должно превышать 75, для Enterprise - неограниченно. Других различий между редакциями SRM нет.
SRM не предъявляет строгих требований к идентичности аппаратных компонентов (серверов и СХД) и конфигурации инфраструктуры в основном и резервном сайте. При ограничении бюджета возможно использование меньшего количества серверов или серверов предыдущего поколения, которых должно быть достаточно для того, чтобы выдержать рабочую нагрузку на время восстановления основного сайта.
Интерфейс SRM не предполагает автоматический запуск плана восстановления, это задача ответственного администратора, который должен оценить критичность сбоя и в нужный момент нажать на “красную кнопку”. Хотя эту задачу и можно автоматизировать с помощью скриптов, но этого крайне не рекомендуется делать.
С точки зрения SRM, сайт – это один или несколько серверов ESXi, подключенных к общей СХД и управляемые одним экземпляром VMware vCenter Server. При развертывании SRM в качестве сайта могут выступать как отдельные ЦОДы, расположенные в сотнях километров друг от друга, или серверные помещения на разных этажах одного здания, так и соседние стойки в одной серверной комнате. Расстояние между ЦОДами ограничено исключительно возможностью организовать каналы передачи данных с требуемыми характеристиками для репликации данных между СХД (см. требования вендора СХД), сам SRM не накладывает здесь никаких ограничений.
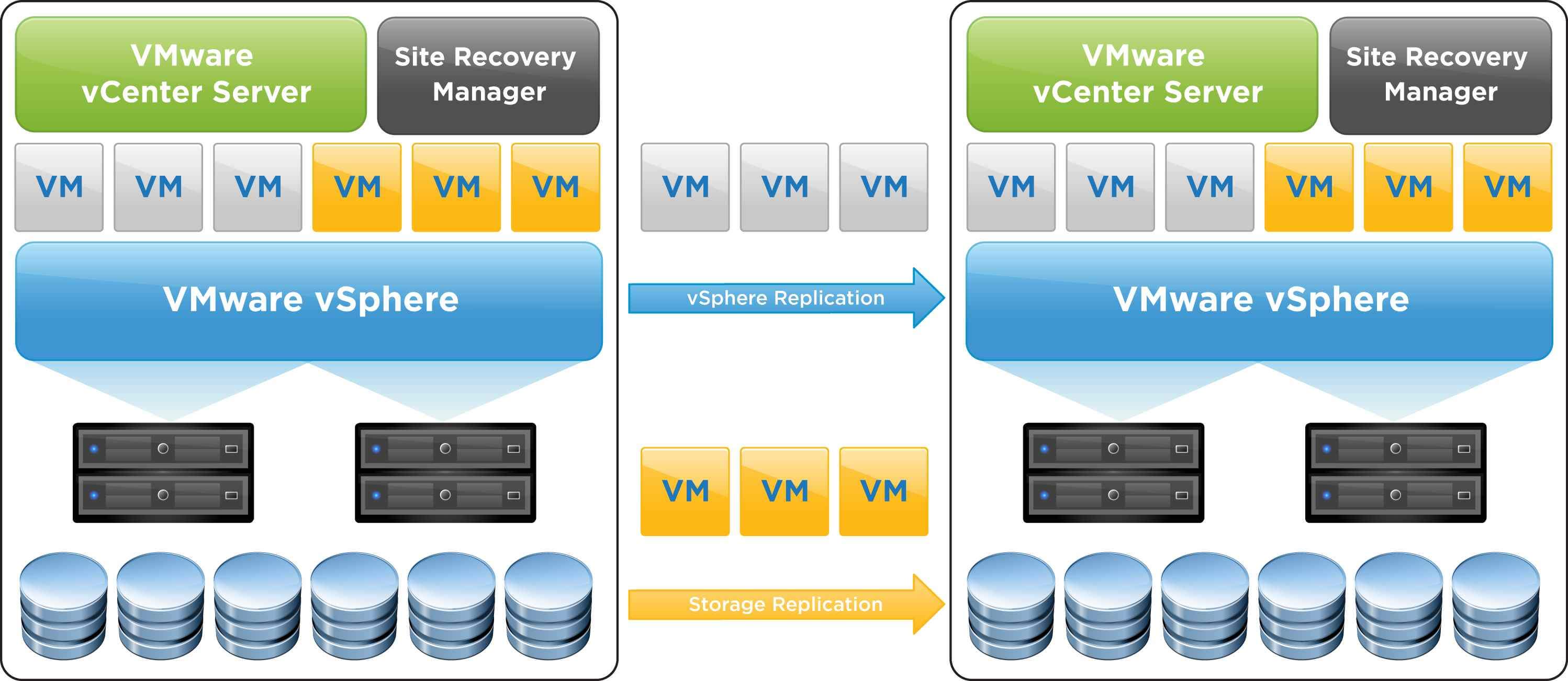
Начиная с версии 5.0 SRM помимо репликации на уровне СХД, имеет и встроенные механизмы репликации.
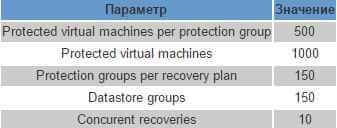
Репликация СХД, как правило, выполняется по отдельным каналам передачи данных (Fibre Channel или iSCSI) может быть как синхронной, так и асинхронной, но реплицирует хранилище VMFS целиком и все ВМ на нем. При репликации средствами СХД следует принимать в расчет следующие лимиты:
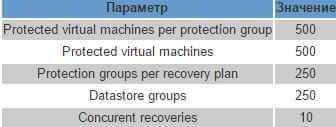
Если при развертывании SRM планируется использовать хранилище, не поддерживающее репликацию, то копирование отдельных ВМ может выполняться с помощью vSphere Replication. Преимущества использования vSphere Replication заключаются в том, что он не требует покупки дополнительных лицензий и настройки репликации на уровне СХД; к недостаткам можно отнести то, что репликация идет по обычной сети, поддерживается только асинхронная репликация (интервал репликации не чаще раз в 15 минут, не реже раз в 24 часа), кроме того невозможно создавать консистентные реплики для приложений внутри ВМ (всевозможные базы данных).
При репликации vSphere Replication следует принимать в расчет следующие лимиты:
При планировании развертывания SRM отдельное внимание следует уделить организации сети в основном и резервном сайтах. Так как практически всем виртуальным машинам для работы требуется доступ в сеть, переезд из одного сайта в другой может быть из-за этого осложнен.
В общем случае можно выделить несколько вариантов организации сети. Каждый из них имеет свои преимущества и недостатки:
- Сквозная IP адресация в обоих сайтах.
- Разные подсети в обоих сайтах.
- Мигрирующая подсеть.
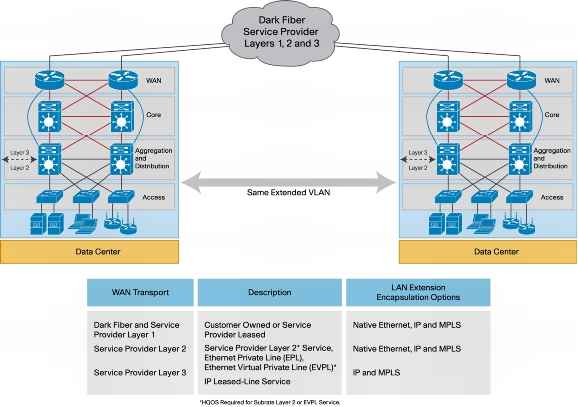
Сквозная IP-адресация позволяет использовать единое адресное пространство во всех сайтах (т.н. Stretched VLAN). Данный вариант является самым простым для администраторов систем виртуализации, но может потребовать больших вложений в модернизацию сетевой инфраструктуры. Одно дело, когда сайты находятся в пределах одного здания на расстоянии нескольких сотен метров, и совсем другое, когда их разделяют сотни километров – такое распределенное решение может быть гораздо сложнее в поддержке, да и аренда или прокладка высокоскоростных линий связи влетит в копеечку.
В случае использования различных сетей (например, 192.168.1.0/24 в основном сайте и 192.168.2.0/24 в резервном), SRM может менять настройки виртуальных адаптеров для ВМ, которые задаются администратором при настройке плана восстановления. В качестве альтернативного варианта может использовать DHCP для назначения сетевых параметров. Однако следует понимать, что далеко не все службы спокойно переносят смену IP адресов, кроме того для некоторых ВМ может потребоваться дополнительная настройка приложений и служб из-за смены адресов.
Наконец все защищаемые ВМ можно располагать в отдельной сети, которая будет “переезжать” в резервный сайт вместе с ВМ, что в общем случае потребует изменения настроек и маршрутизации на сетевом оборудовании.
При установке и начальной конфигурации, серверы SRM настраиваются на взаимодействие с серверами vCenter Server и СХД в локальном сайте. Для интеграции с СХД на серверы SRM устанавливается специализированный агент – Storage Replication Adapter (для каждой поддерживаемой модели СХД существует свой SRA). При помощи данного агента SRM может подключаться к СХД, получать информацию о хранилищах данных и контролировать репликацию. SRA доступны для загрузки с сайта VMware. Список совместимых СХД можно посмотреть здесь (http://www.vmware.com/support/srm/srm-storage-partners.html).
Для хранения конфигурации SRM используется база данных Microsoft SQL Server (можно использовать Express редакцию). Для каждого сайта необходим свой собственный сервер БД. Кроме того, в каждом сайте должно быть развернуто, по крайней мере, по одному серверу-контроллеру домена и DNS серверу для корректной работы восстанавливаемых служб и приложений. ВМ с контроллерами домена вообще не рекомендуется защищать с помощью SRM из-за USN Rollback.
После выполнения установки и первоначальной настройки SRM, в резервном сайте создается план восстановления (Recovery Plan) на случай сбоя, который определяет перечень ВМ, подлежащих восстановлению, порядок восстановления ВМ, а также набор дополнительных операций (исполняемых сценариев), выполняемые при восстановлении. SRM позволяет администратору создавать несколько планов для разных случаев и при необходимости активировать любой из них.
На сервере SRM в основном сайте выполняется настройка защищаемой группы (Protection Group), включающей в себя ВМ, подлежащих восстановлению в резервном сайте. Данная группа добавляется в план восстановления на сервере SRM в резервном сайте, который администратор виртуальной инфраструктуры запускает в случае сбоя в основном сайте.
SRM поддерживает два варианта переключения (Failover) с основного сайта не резервный: запланированный и незапланированный.
В случае запланированного переключения, когда требуется провести какие-либо работы в основном сайте (например: отключение питания, перенос оборудования и т.п.), администратор заранее запускает процесс миграции ВМ. SRM выключает все защищаемые виртуальные машины в основном сайте, запускает репликацию на СХД и проверяет, что она успешно выполняется, после чего запускает реплики ВМ в резервном сайте. Тем самым все ВМ переносятся в резервный сайт, и гарантируется целостность данных внутри ВМ, пускай и ценой некоторого кратковременного простоя.
В случае незапланированного переключения (например, при пожаре, отключении электроэнергии), когда основной сайт недоступен, SRM запускает ВМ, используя последнюю актуальную реплику данных на СХД в резервном сайте. В этом случае не может гарантироваться целостность данных (если только репликация не гарантирует консистентность на уровне приложений).
Помимо функционала восстановления инфраструктуры в резервном сайте, SRM также предоставляет возможность переноса ВМ обратно из резервного сайта в основной (Failback). Для этого администратор предварительно должен запустить операцию Reprotect, которая, по сути, перенастраивает репликацию СХД и все защищаемые группы и планы восстановления в обратную сторону, т.е. меняет местами основной и резервный сайты. После чего может быть выполнено запланированное переключение с резервного сайта на основной (SRM погасит ВМ в резервном сайте, выполнит репликацию и запустит реплики ВМ в основном сайте).
Однако это работает только в том случае, если SRM, vCenter Server и СХД в основном сайте доступны. Если СХД или SRM в основном сайте были уничтожены, то придется настраивать репликацию и SRM с нуля, также как при развертывании нового SRM.
Наконец, SRM предоставляет возможность проведения тестового восстановления ВМ без необходимости приостанавливать работу ВМ в основном сайте, что, на мой взгляд, является одним из самых ценных качеств данного продукта. SRM на время приостанавливает репликацию между основным и резервным сайтом и запускает тестовые ВМ в резервном сайте в изолированной сети, не имеющей доступ в производственную сеть. После проверки работы SRM выключает резервные ВМ и повторно запускает репликацию на СХД. Следует отметить, что многие СХД поддерживают тестовое восстановление без приостановки репликации. Таким образом вы можете потренироваться на кошках и проверить правильность работы плана восстановления без риска что-нибудь испортить.
Заключение
Сегодня мы рассмотрели ключевые возможности SRM и варианты его использования для защиты виртуальной инфраструктуры. В следующий раз мы рассмотрим процедуру подготовки и установки SRM
Популярные Похожие записи:
 Как делать резервное копирование VMware и oVirt в среде Multiple-hypervisor?
Как делать резервное копирование VMware и oVirt в среде Multiple-hypervisor?- Ошибка DRS на кластере ESXI
- Что такое виртуальный сетевой адаптер и в каких случаях он может пригодиться?
- Режимы кворума отказоустойчивого кластера Windows в группах доступности AlwaysOn
- Центр обработки данных, основные понятия
- Словарь системного администратора


