
Замена сломанного диска на Dell SC 5020
![]() Добрый день! Уважаемые читатели и гости блога. В последнее время я очень часто стал писать про системы хранения данных Dell SC5020, вы просто не могли этого не заметить, одной из последних публикаций была ситуация, что у меня перестал быть доступен один из FC портов. В сегодняшней статья я расскажу, как у меня уже сломался SSD диск, который мы доблестно заменили и произвели дополнительные действия по его вводу в эксплуатацию. Понимаю, что для кого-то это тривиальная вещь, но у меня на данном оборудовании это произошло впервые за 5 лет. Поэтому я и решил сделать памятку себе.
Добрый день! Уважаемые читатели и гости блога. В последнее время я очень часто стал писать про системы хранения данных Dell SC5020, вы просто не могли этого не заметить, одной из последних публикаций была ситуация, что у меня перестал быть доступен один из FC портов. В сегодняшней статья я расскажу, как у меня уже сломался SSD диск, который мы доблестно заменили и произвели дополнительные действия по его вводу в эксплуатацию. Понимаю, что для кого-то это тривиальная вещь, но у меня на данном оборудовании это произошло впервые за 5 лет. Поэтому я и решил сделать памятку себе.
Процедура диагностику вылетевшего SSD диска на Dell SC 5020
С утра система мониторинга прислала занимательные сообщения об ошибках.
⛔️ Важно : SC5020: SC5020_Dell : Global status of SC5020 is critical
❌ Чрезвычайно важно : SC5020: SC5020_Dell : Disk 11 is down on SC5020
Alert created on controller 'Dell[364554]' for object [internal ref: 'DiskFolderClass 3 8'] - [SpareHunger]: Disk Folder Assigned requires 1 additional disks of class Read-Intensive SSD to satisfy internal sparing requirements
Alert created on controller 'Dell[364554]' for object [internal ref: 'Disk 11 Position[1-4]'] - [Health]: Disk 11 health code change: PredictedError SN: S40GNX0M800683
Из которых стало понятно, что произошло нехорошее событие с дисками на СХД. Первым делом я побежал смотреть состояние оборудования с помощью веб-интерфейса. На главном дашборде в разделе "Alerts" были 7 критических событий. Обратите внимание, что в разделе "Inventory" видно общее количество диков, их 30, 29 зеленые и один с ошибкой.
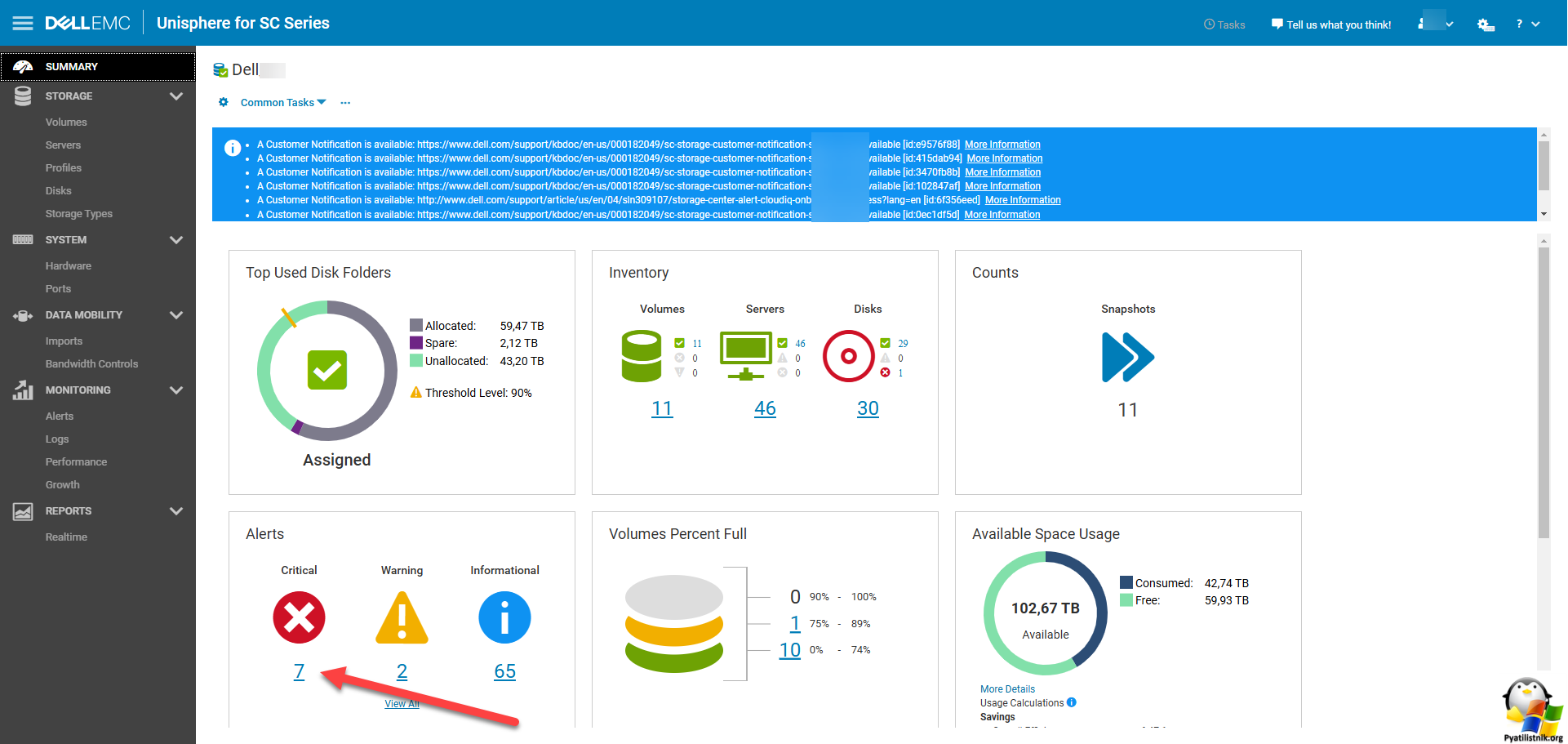
Далее я вам советую всегда обратиться к разделу "Logs". Тут было важное событие, что диск 11 скоро выйдет из строя, имея статус "PredictedError" и уже удален из массива, так же сообщается что он готов к замене или удалению.
Disk 11 SN: S40GNX0M800683 failed [PredictedError] and is ready to be removed
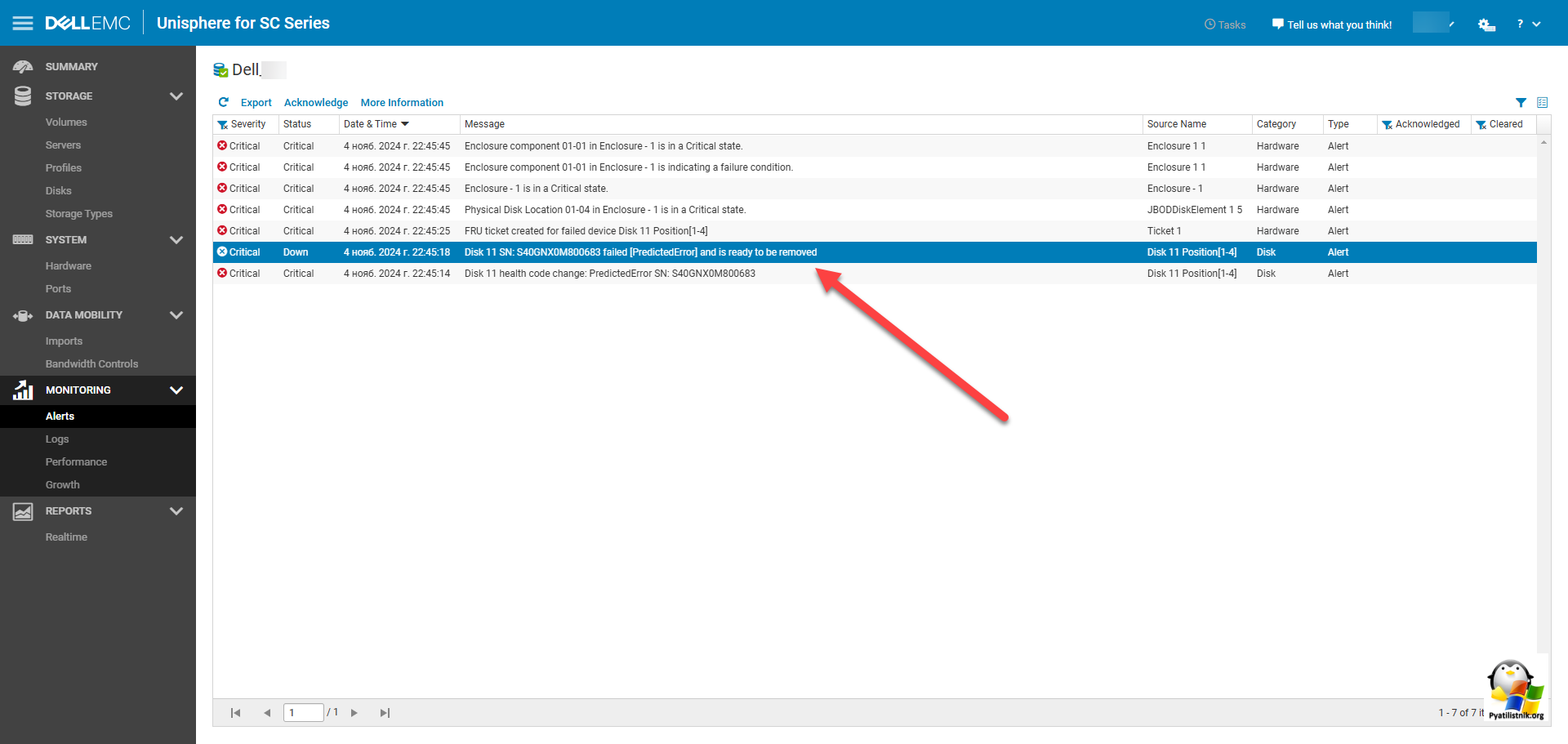
Статус "PredictedError" у диска в системах хранения данных (СХД) Dell указывает на то, что контроллер или программное обеспечение системы хранения предсказало потенциальную ошибку или сбой в работе данного диска. Это может быть связано с различными факторами, такими как:
- Состояние диска: Диск может иметь проблемы с его физическим состоянием, например, износ или повреждение.
- SMART-данные: Многие жесткие диски и SSD поддерживают технологию SMART (Self-Monitoring, Analysis, and Reporting Technology), которая отслеживает различные параметры работы устройства. Если какие-либо из этих параметров выходят за пределы допустимых значений, это может привести к статусу "PredictedError".
- Ошибки чтения/записи: Если диск часто сталкивается с ошибками чтения или записи, это также может вызвать предупреждение о предсказанной ошибке.
- Заканчивается TBW
Алгоритм замены SSD диска на СХД Dell SC 5020
Сразу скажу, что паниковать не стоит. Так как в данном типе СХД особый проприетарый ADAPT RAID, поэтому данные размазаны по всем дискам. Да и процедуру замены мы уже делали на RAID PERC H740P Adapter и LSI контроллере, где был статус у диска "Predictive failure".
RAID ADAPT (Advanced Data Protection Technology) — это технология, разработанная компанией Dell для повышения надежности и доступности данных в системах хранения. Она предназначена для защиты от потери данных и обеспечения высокой производительности при работе с RAID-массивами.
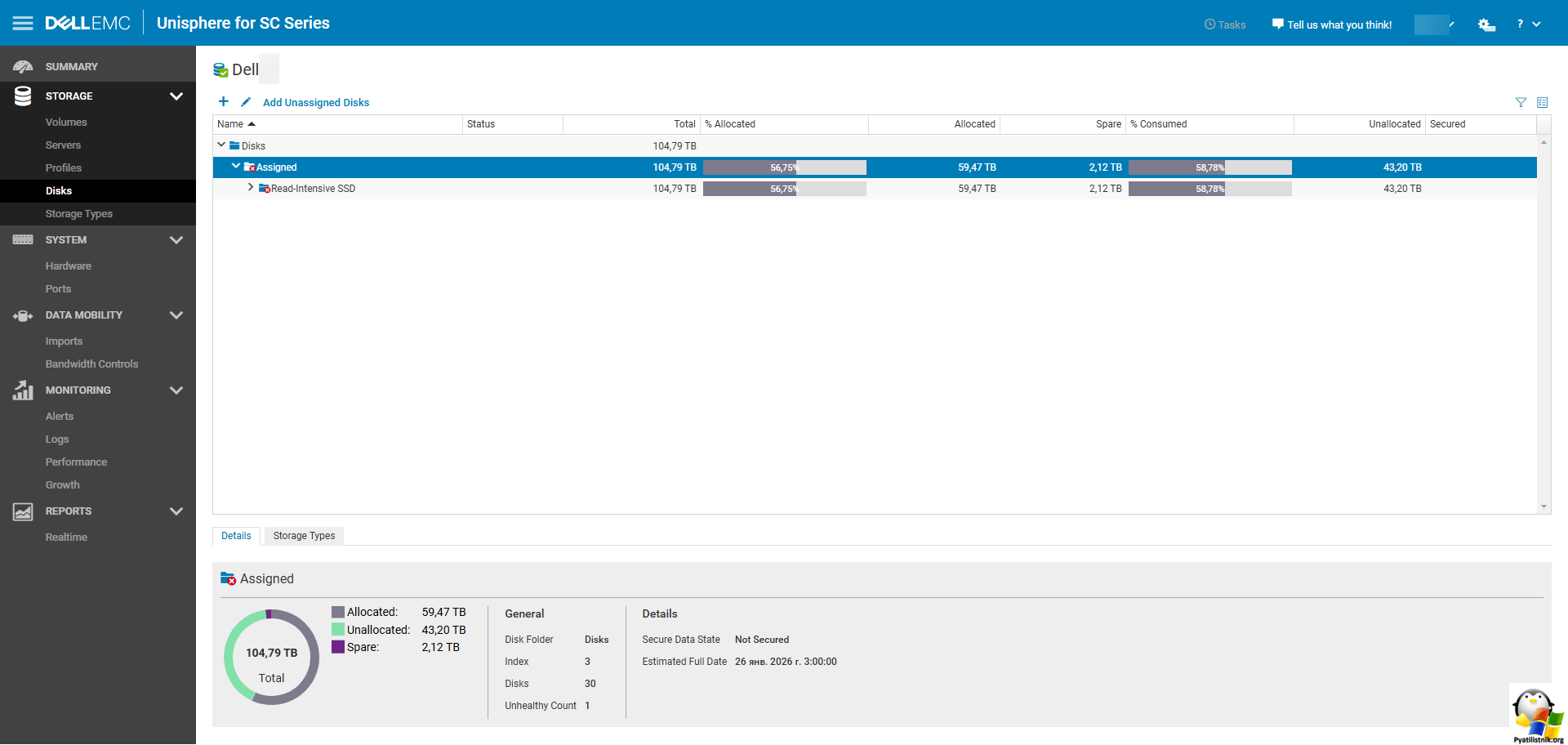
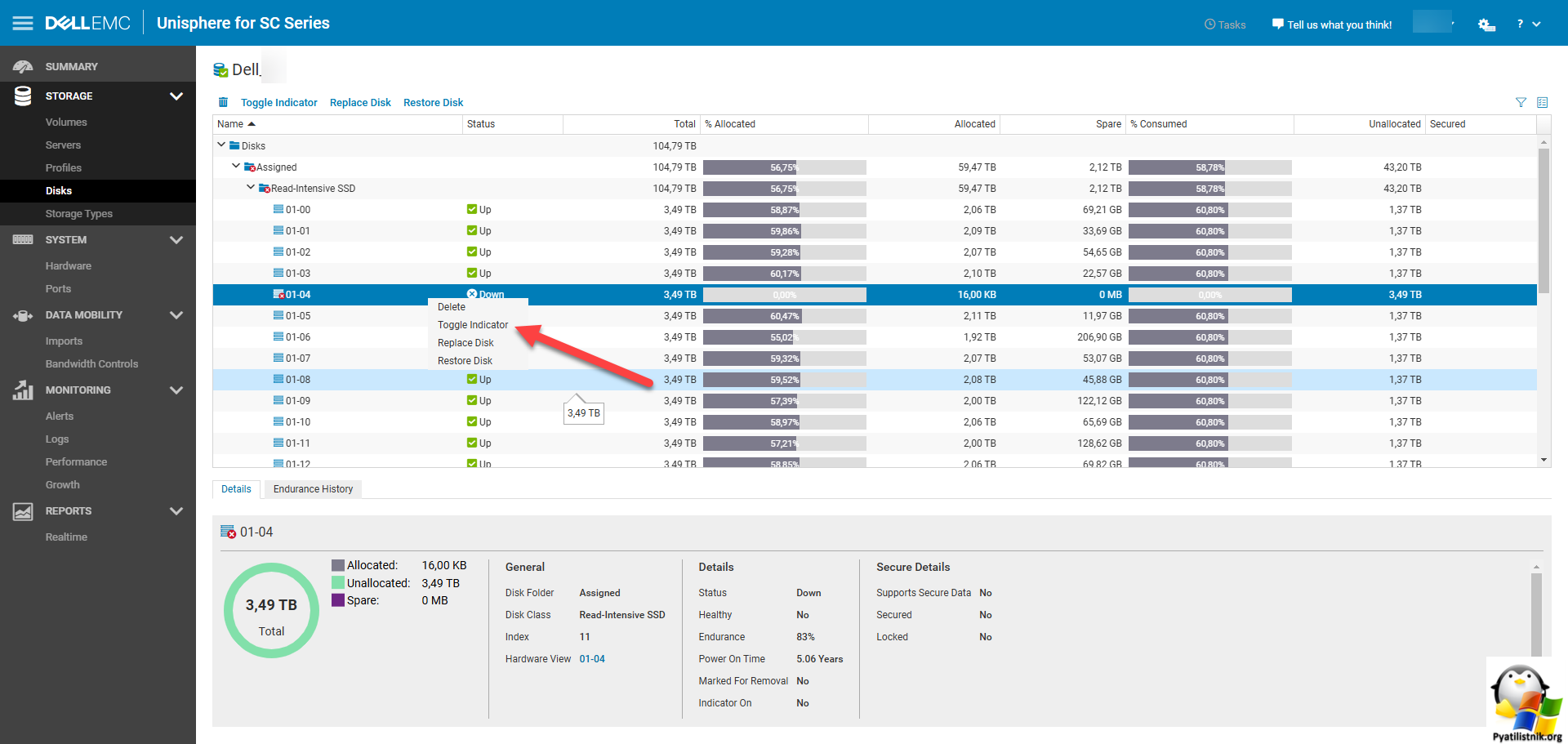
Если вы видите статус "PredictedError", рекомендуется предпринять следующие шаги: Откройте раздел "Disks - Assigned". Разверните там папку "Read-intensive SSD".
Найдите сбойный SSD диск. У него будет статус "Down". Обратите внимание, что его использование в RAID массиве ADAPT 0%, то есть данных на нем нет, они все были уже перенесены на другие диски.
Обратите внимание на время работы диска (5 лет) и степень его износа Endurance всего 17%, значит он получил статус PredictedError не из-за SMART показателей. Еще помните, что выше ругалось на Disk 11, это был не его номер, а "Index".
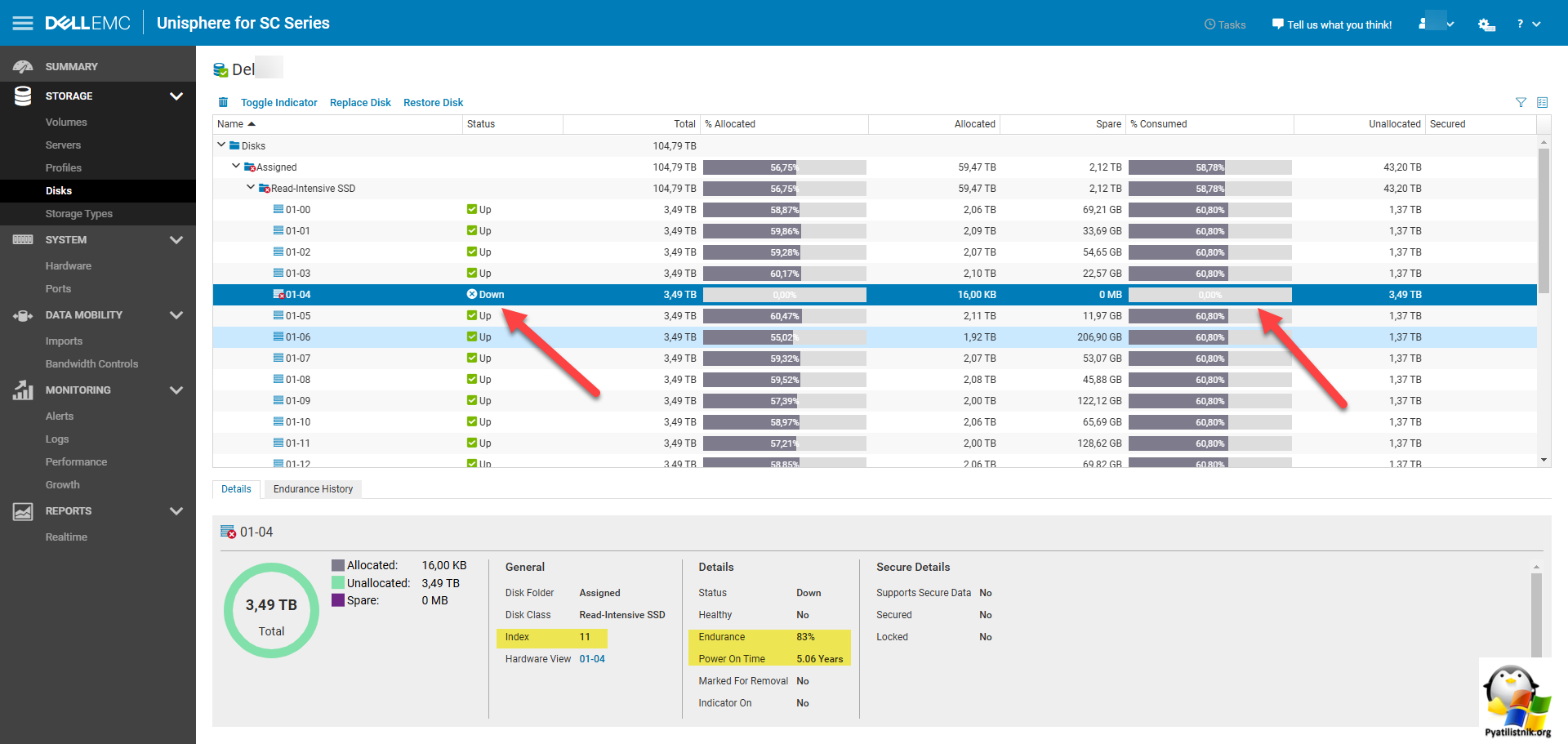
Через правый клик вы можете произвести подсветку диска "Toggle indicator", чтобы его проще было найти при замене.
Ранее я рассказывал про включение индикации на серверах и дисках в статьях: "Как подсветить диски на сервере HP ProLiant DL380 G7" и "Как подсветить блейды в IBM BladeCenter"
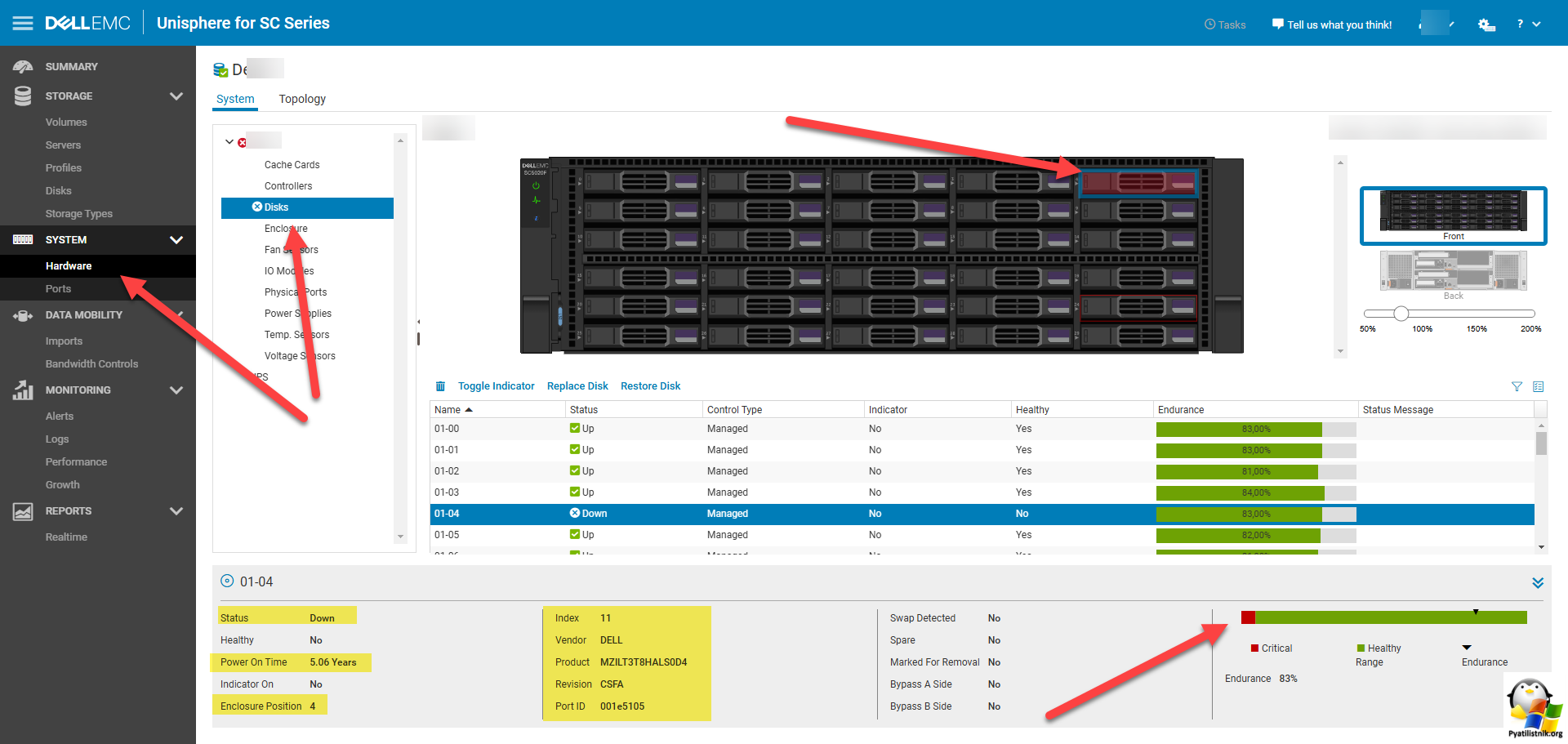
Еще более подробную информацию вы можете найти в разделе "System - Hardware - Disks", тут из полезного будет:
- Статус диска
- Время работы диска
- Его позиция в корзине (Enclosure Possition)
- Номер индекса
- Вендор
- Продукт
- Шкала износа диска
- Картинка с визуальным отображением про какой диск идет речь.
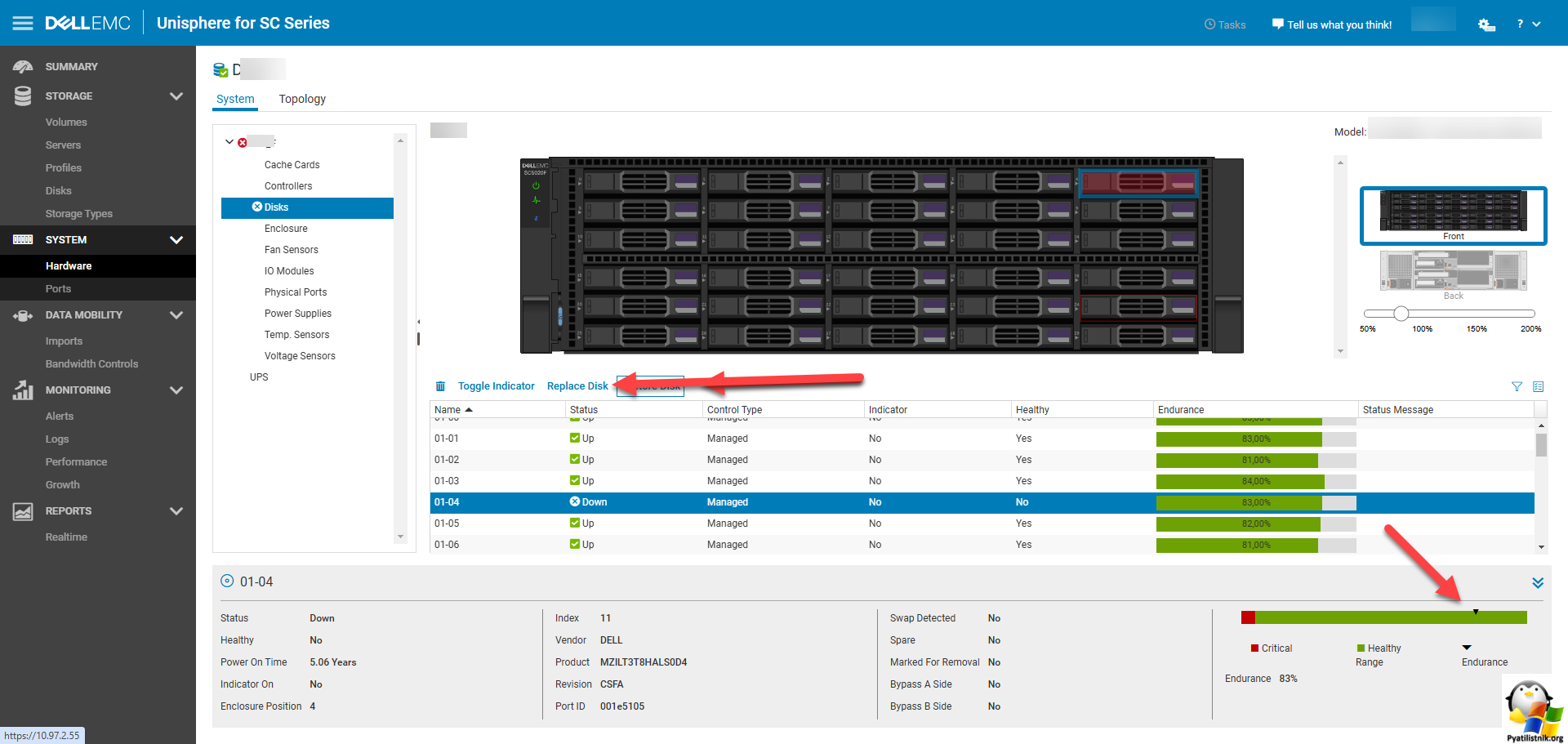
Процедура замены диска на системах хранения данных Dell SC5020 очень простая. Выберите диск и нажмите кнопку "Replace Disk".
Или то же самое можно сделать в Dell Storage Manager Client.
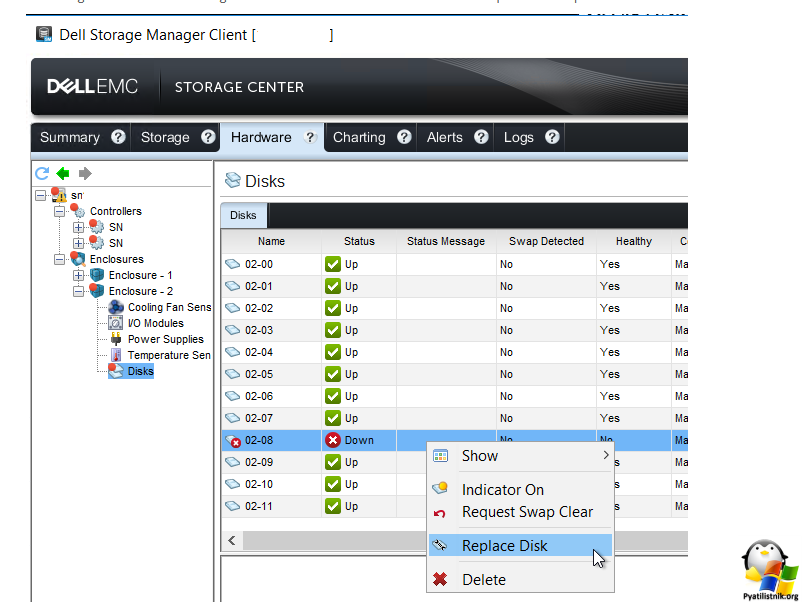
Следуйте инструкциям по физическому извлечению, а после извлечения неисправного диска нажмите далее. Будет небольшой мастер, если все сделано верно, то увидите заветную фразу "Disk replacement status - The disk replacement was successful"
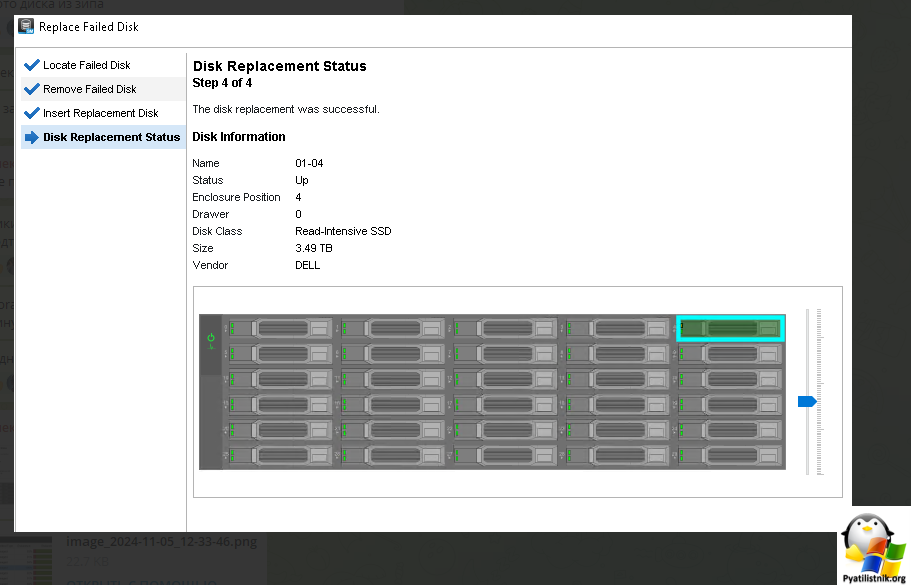
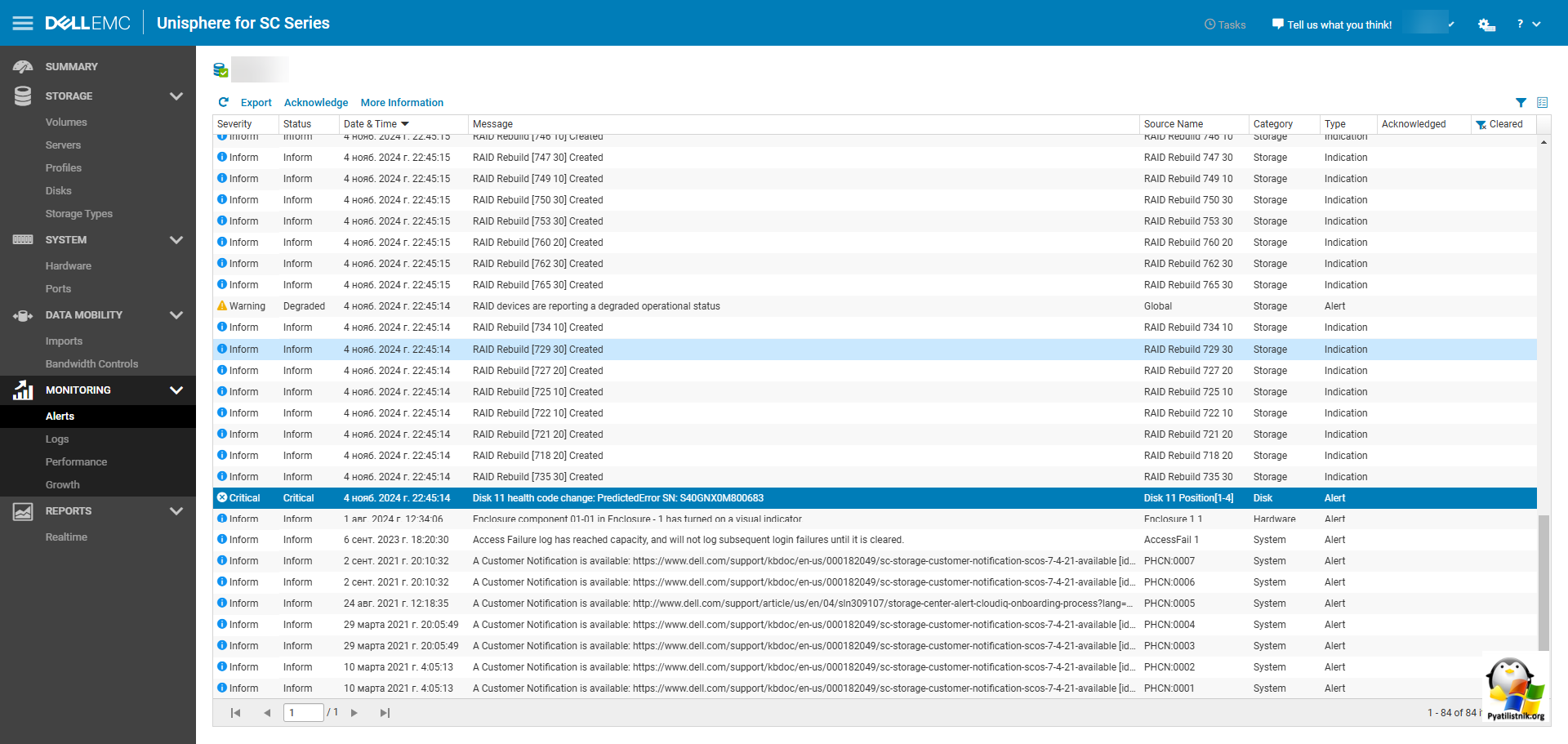
Дожидаемся в логах окончания ребилда RAID массива.
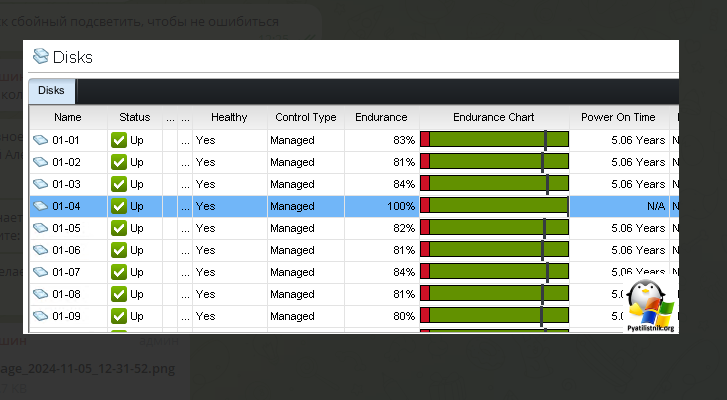
Как видно из скриншоты новый диск успешно определился, его степень износа 0%, время работы N/A.
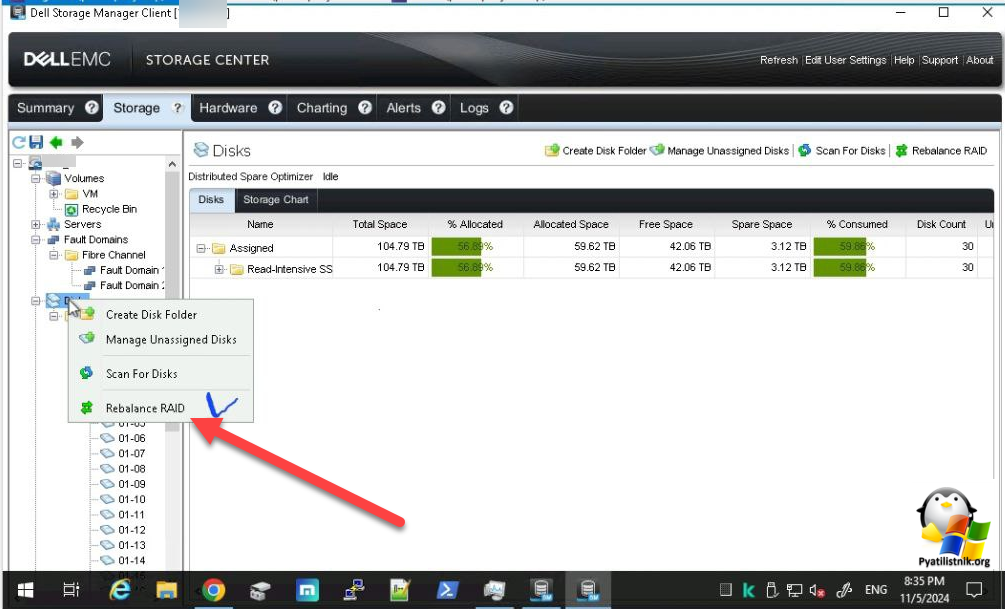
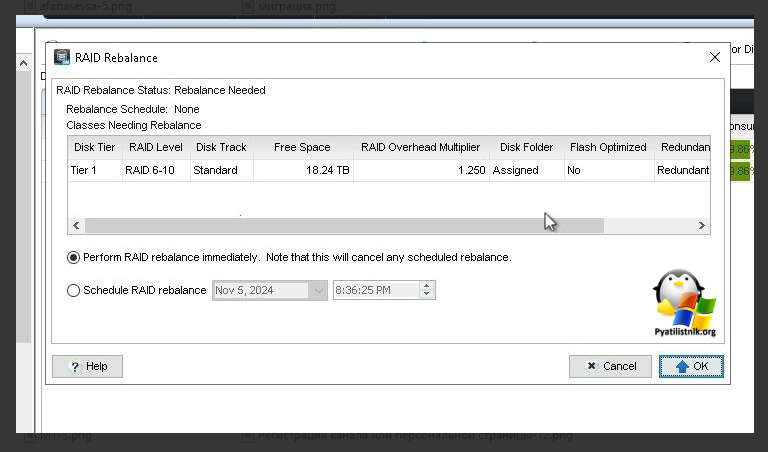
Остается в вечернее время выполнить "Rebalance RAID". Процедура Rebalance RAID (перебалансировка RAID) в системах хранения данных (СХД) Dell SC5020 предназначена для оптимизации распределения данных между дисками в RAID-массиве. Эта процедура может быть необходима в следующих случаях:
- Добавление новых дисков: Когда в массив добавляются новые диски, данные могут быть неравномерно распределены. Перебалансировка помогает перераспределить данные, чтобы использовать все доступные ресурсы и улучшить производительность.
- Замена дисков: Если диск в массиве был заменен, особенно на диск с другой емкостью, может потребоваться перебалансировка для оптимизации использования пространства.
- Изменение конфигурации RAID: При изменении уровня RAID
- Устранение деградации производительности: Со временем данные могут накапливаться неравномерно, что может привести к снижению производительности. Перебалансировка помогает улучшить скорость чтения и записи, перераспределяя данные более равномерно.
Так же интересно - Виды RAID, их плюсы и минучы
Процесс перебалансировки RAID
Процесс обычно включает следующие шаги:
- Анализ текущего состояния массива: Система анализирует текущее распределение данных и определяет необходимость в перебалансировке.
- Перераспределение данных: Система начинает перемещать данные между дисками, чтобы достичь более равномерного распределения.
- Мониторинг и завершение: Процесс мониторится для обеспечения его успешного завершения. По окончании перебалансировки массив должен работать более эффективно.
Выберите раздел "Disks" и в контекстном меню найдите кнопку "Rebalance RAID", нажмите на нее.
Увидите, что статус говорит о необходимости запуска процедуры. Так как я делаю это в вечернее время, значит могу сделать немедленно, либо можно настроить по расписанию.
• Процедура может занимать некоторое время в зависимости от объема данных и конфигурации массива. Важно следить за состоянием системы во время перебалансировки, так как она может временно повлиять на производительность. Рекомендуется выполнять перебалансировку в период низкой активности, чтобы минимизировать влияние на пользователей
На этом у меня все. Мы с вами успешно заменили сбойный SSD диск на новый и восстановили штатную работоспособность СХД Dell SC5020. С вами был Иван Сёмин, автор и создатель IT портала Pyatilistnik.org.
Дополнительно
https://www.dell.com/support/kbdoc/en-us/000117921/replacing-disks-in-sc-series-via-the-dell-storage-manager-client



